

Dify+DeepSeek
概念
RAG(Retrieval-Augmented Generation)是一种结合了信息检索(Retrieval)和文本生成(Generation)的技术。它主要用于自然语言处理(NLP)任务,特别是在问答系统和对话系统中。
RAG模型通常包括两个主要组件:
- 检索器(Retriever) :负责从大规模文档集合中检索出与输入相关的文档或段落。
- 生成器(Generator) :利用检索到的信息生成最终的文本输出。
RAG模型的一个典型应用是在开放域问答系统中,系统需要从大量文档中找到相关信息,并生成一个简洁、准确的回答。通过结合检索和生成,RAG能够更好地处理复杂的问题,并提供更高质量的答案。
热门项目
| 项目 | Star 数量 | 持续维护性 | 社区活跃度 | 代码质量 | 版权信息 |
|---|---|---|---|---|---|
| QAnything | 10.6k | ⭐️ | ⭐️⭐️ | ⭐️⭐️⭐️ | Apache-2.0 |
| RAGFlow | 11.2k | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️ | Apache-2.0 |
| langchain-chatchat | 29.7k | ⭐️⭐️⭐️ | ⭐️⭐⭐️ | ⭐️⭐️ | Apache-2.0 |
| Dify | 36.7k | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | 附加条件的 Apache-2.0 |
| FastGPT | 15.3k | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️ | 附加条件的 Apache-2.0 |
langchain-chatchat
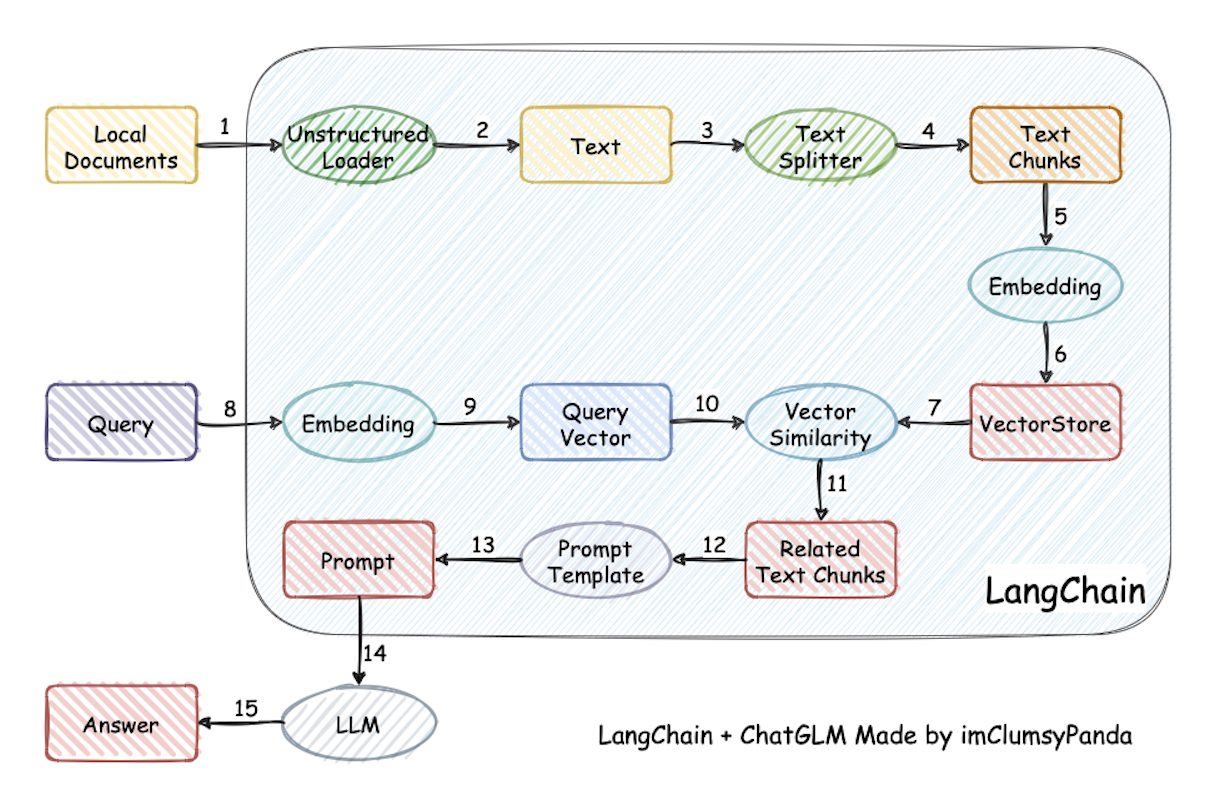
- 强调支持离线私有化部署,对于私有化部署支持完善,但是从 langchain-0.3.0 之后部署方式也发生了变化,与其他项目的差异不大;
Dify
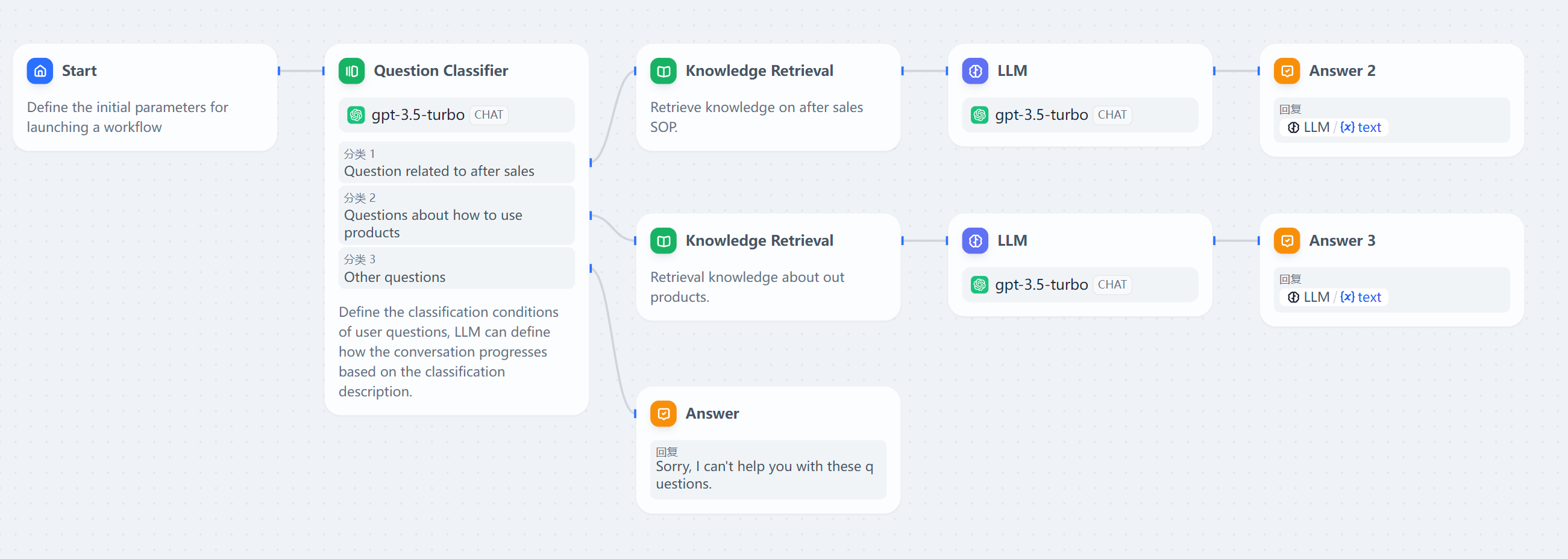
- 丰富的召回模式,支持跨知识库召回;
在AI知识库中,“召回”(Recall)是一个重要的评估指标,通常用于衡量模型在检索或分类任务中的表现。召回率表示模型能够正确检索或识别出所有相关结果的比例。
具体来说,召回率的计算公式为:召回率=正确检索或识别的相关结果数量所有相关结果的总数量召回率=所有相关结果的总数量正确检索或识别的相关结果数量
例如,在一个信息检索系统中,假设总共有100个相关文档,而系统检索出了80个相关文档,那么召回率就是80%。
召回率与另一个常用指标“精确率”(Precision)不同,精确率衡量的是检索结果中相关结果的比例。在实际应用中,召回率和精确率往往是相互制约的,提高召回率可能会导致精确率下降,反之亦然。因此,通常需要在两者之间找到一个平衡点。
在AI知识库的应用中,召回率的高低直接影响到用户能否获取到全面的相关信息。高召回率意味着系统能够尽可能多地找到相关结果,减少遗漏,这对于需要全面信息的任务(如法律检索、医学诊断等)尤为重要。
- 支持 QA 模式,可以基于原始文档生成问答对进行召回;
- 支持工作流编排;
FastGPT
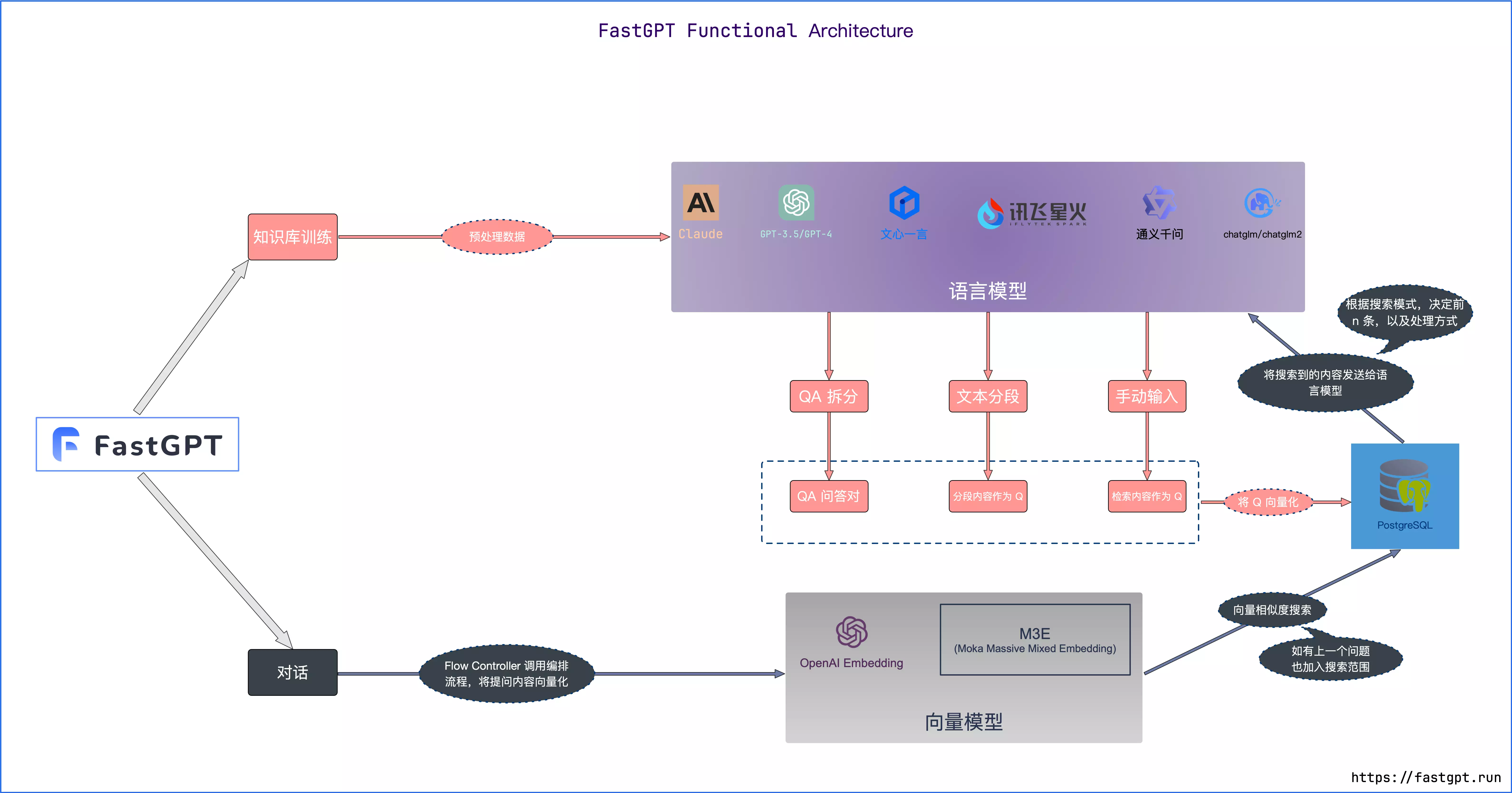
- 支持 QA 模式,可以基于原始文档生成问答对进行召回;
- 支持工作流编排;
DeepSeek-r1:8b
1 - 下载Ollama
C:\Users\Purezento>ollama -vollama version is 0.5.4-0-g08b89162 - 下载模型
ollama run deepseek-r1:8b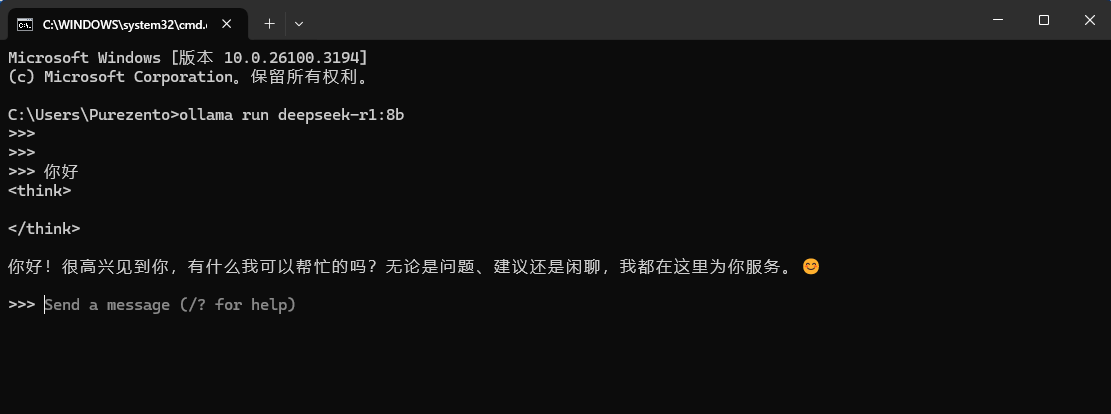
3 - 激活A卡
修改 ollama-for-amd
从 log 中可以看到 ollama 没有跑在显卡上,输出没有发现兼容的显卡
source=amd_windows.go:138 msg="amdgpu is not supported (supported types:[gfx1103])" gpu_type=gfx1031source=gpu.go:386 msg="no compatible GPUs were discovered"如果是A卡,下载这个项目
ollama for amd
查询自己的显卡
gfx1032
System requirements (Windows) — HIP SDK installation (Windows)
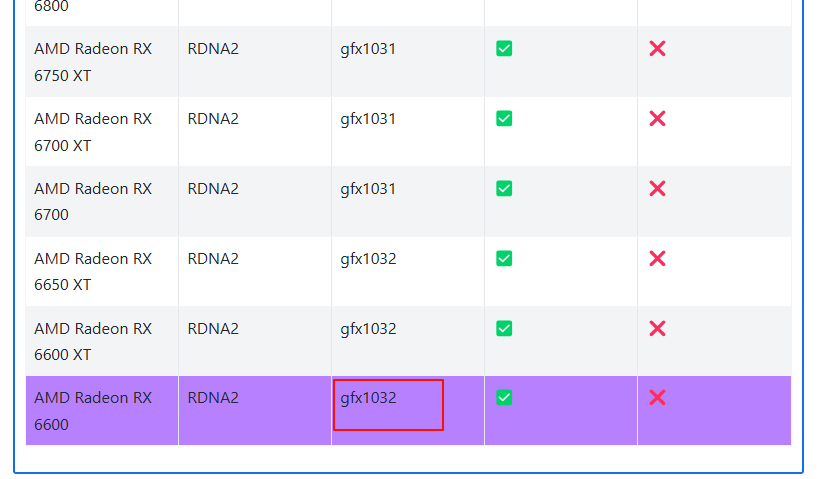
查找适合自己的,我这边是gfx1032
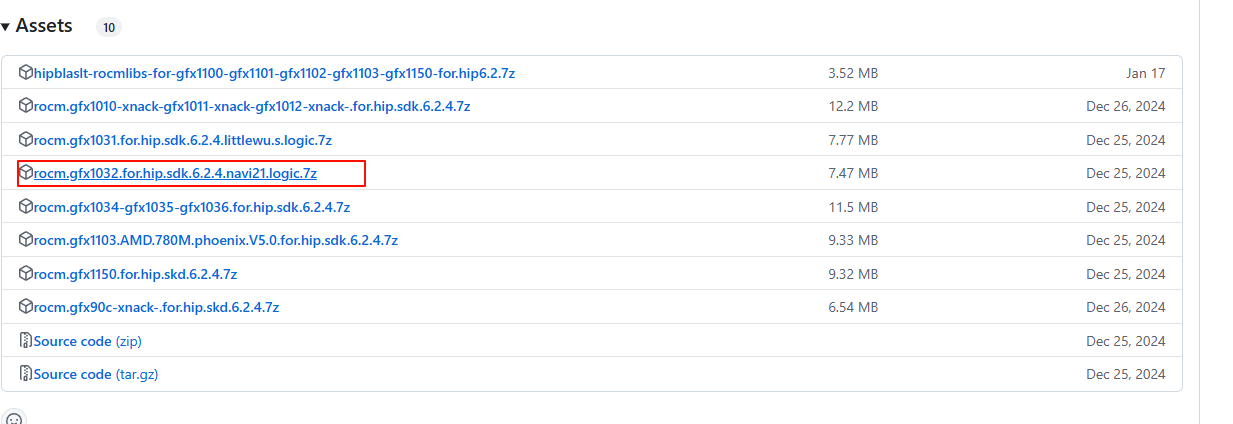
再把这个压缩包进行解压后,替换魔改的ollama安装文件夹的问题。替换后,重启下电脑,你的显卡就能激活了。
打开软件安装目录,比如这是我的安装路径 C:\Users\Purezento\AppData\Local\Programs\Ollama
- 将压缩包中的
rocblas.dll替换C:\Users\Purezento\AppData\Local\Programs\Ollama\rocblas.dll - 将压缩包中的
library文件夹替换C:\Users\Purezento\AppData\Local\Programs\Ollama\rocblas\library
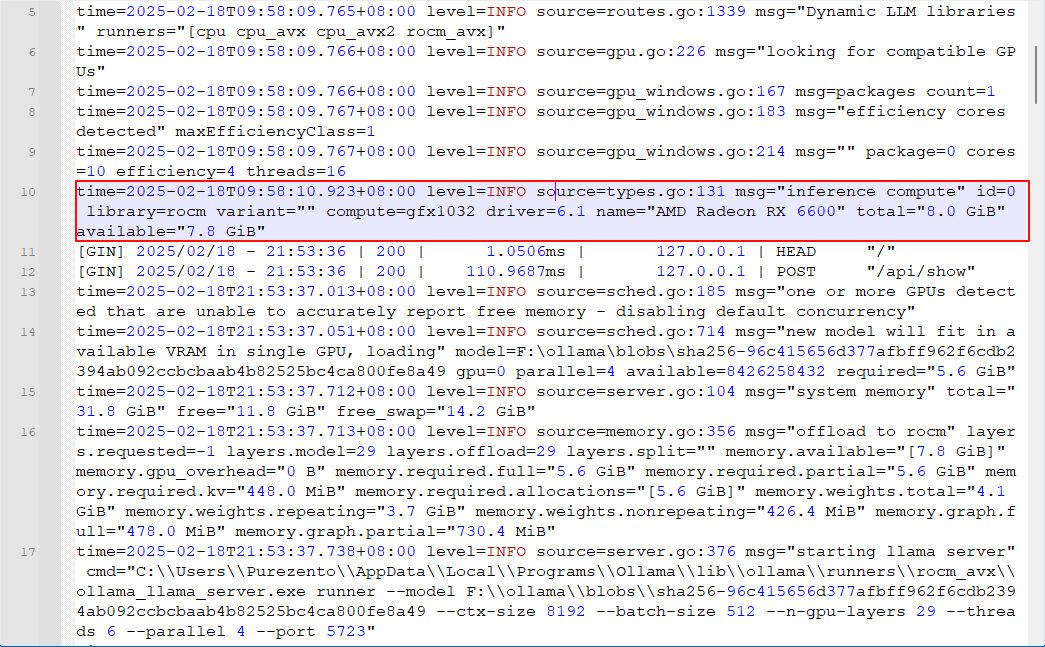
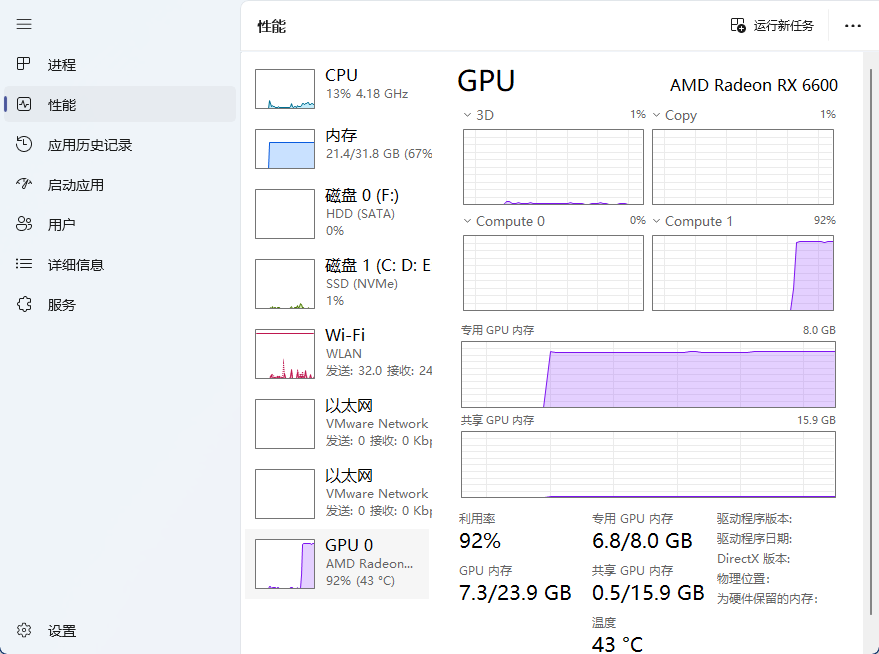
这里也提一下如何判断显卡激活。打开任务管理器,在提问的时候,看是CPU飙升还是GPU飙升,如果GPU飙升,就是显卡激活了。
Dify
克隆 Dify 代码仓库
克隆 Dify 源代码至本地环境。
# 假设当前最新版本为 0.15.3git clone https://github.com/langgenius/dify.git --branch 0.15.3启动 Dify
-
进入 Dify 源代码的 Docker 目录
cd dify/docker -
复制环境配置文件
cp .env.example .env -
启动 Docker 容器
根据你系统上的 Docker Compose 版本,选择合适的命令来启动容器。你可以通过
$ docker compose version命令检查版本,详细说明请参考 Docker 官方文档:- 如果版本是 Docker Compose V2,使用以下命令:
docker compose up -d- 如果版本是 Docker Compose V1,使用以下命令:
docker-compose up -d
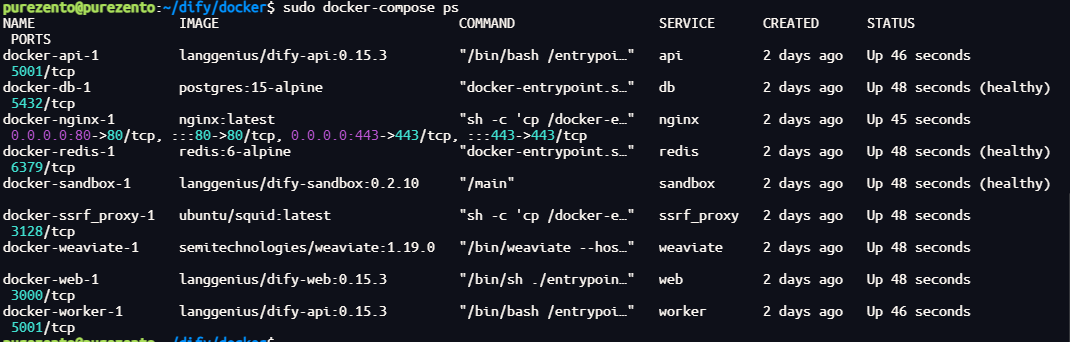
运行命令后,你应该会看到类似以下的输出,显示所有容器的状态和端口映射:

最后检查是否所有容器都正常运行:
docker compose ps在这个输出中,你应该可以看到包括 3 个业务服务 api / worker / web,以及 6 个基础组件 weaviate / db / redis / nginx / ssrf_proxy / sandbox 。
通过这些步骤,你应该可以成功在本地安装 Dify。
安装应用
在浏览器地址栏中输入“ http://192.168.4.25/install”即可开始安装,我是因为dify部署在虚拟机上,所以要访问的是虚拟机的ip,这边建议虚拟机用桥接,这样你下载docker可以经过你本地电脑的代理
设置完账户后进行登录
添加模型
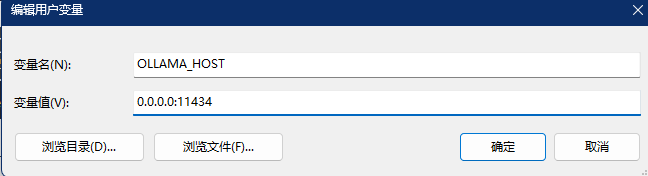
这里需要注意,因为ollama默认只支持本地访问,我的dify是部署在虚拟上,所以是局域网环境,所以要你还得设置一下环境变量,虚拟机才能访问到我主机的ollama
选择【模型供应商】,找到对应的 Ollama,点击【添加模型】
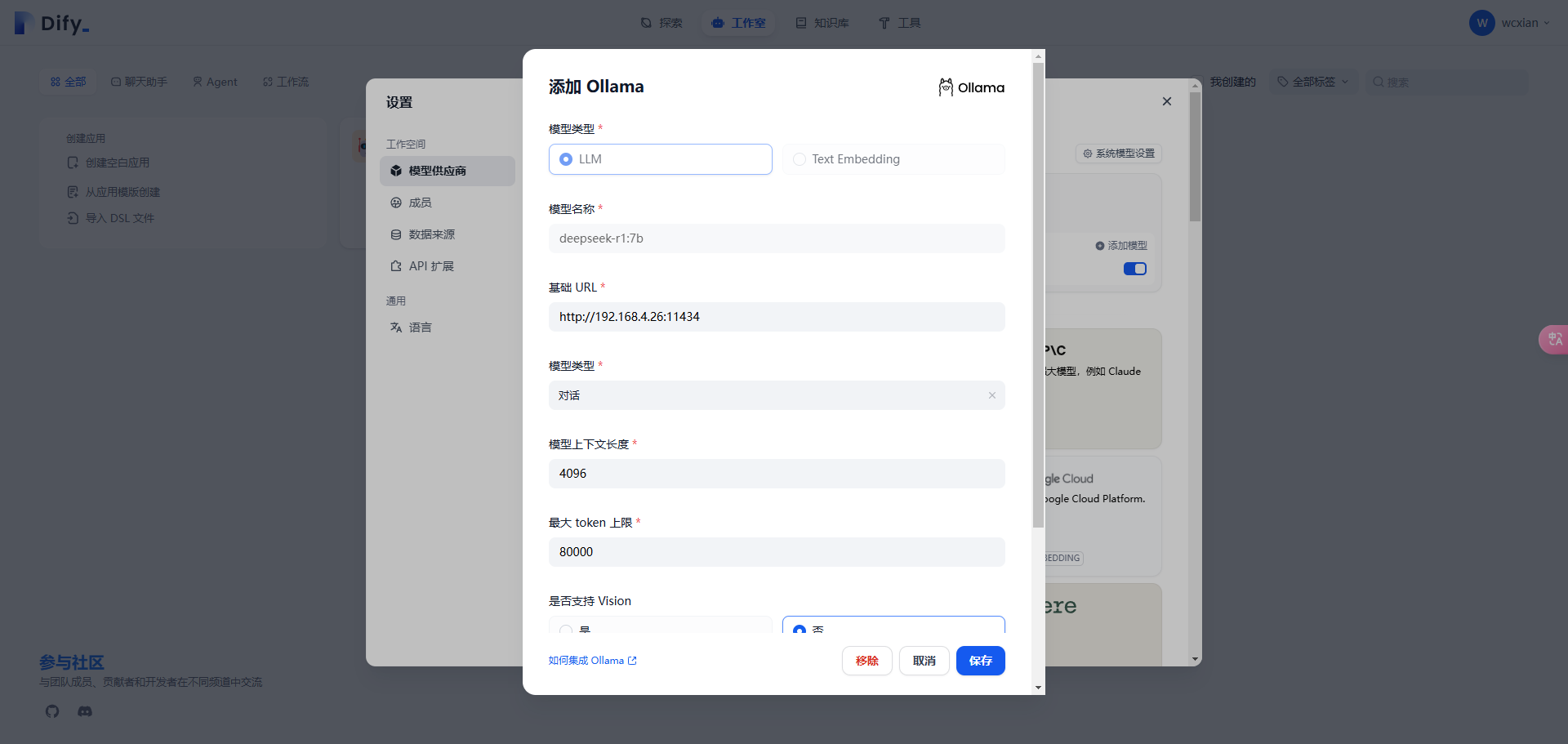
添加好模型后,接下来是设置系统模型,刷新网页。点击右上角用户名下的【设置】,选择【模型供应商】,点击右侧的【系统模型设置】
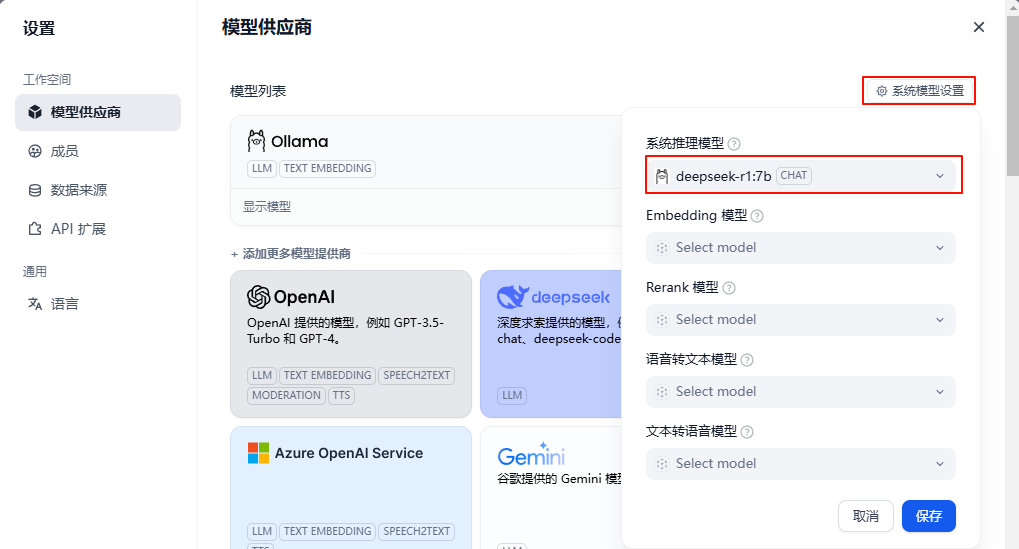
到此,Dify就与前面部署的本地大模型关联起来了。
创建应用
新建一个空白应用

选择【聊天助手】,输入自定义应用名称和描述,点击【创建】
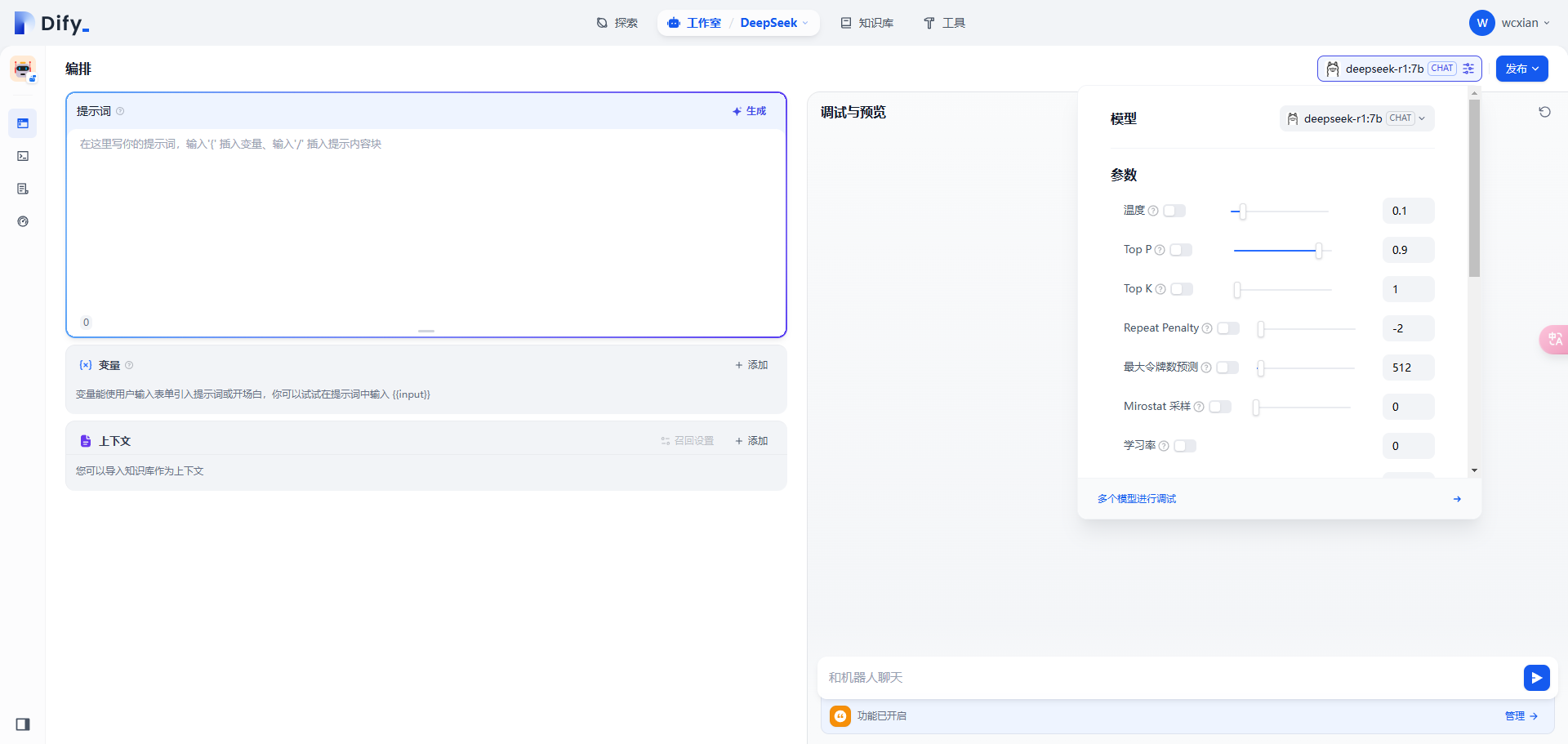
右上角选择合适的模型(如 DeepSeek 或 Ollama),并配置相关参数
测试
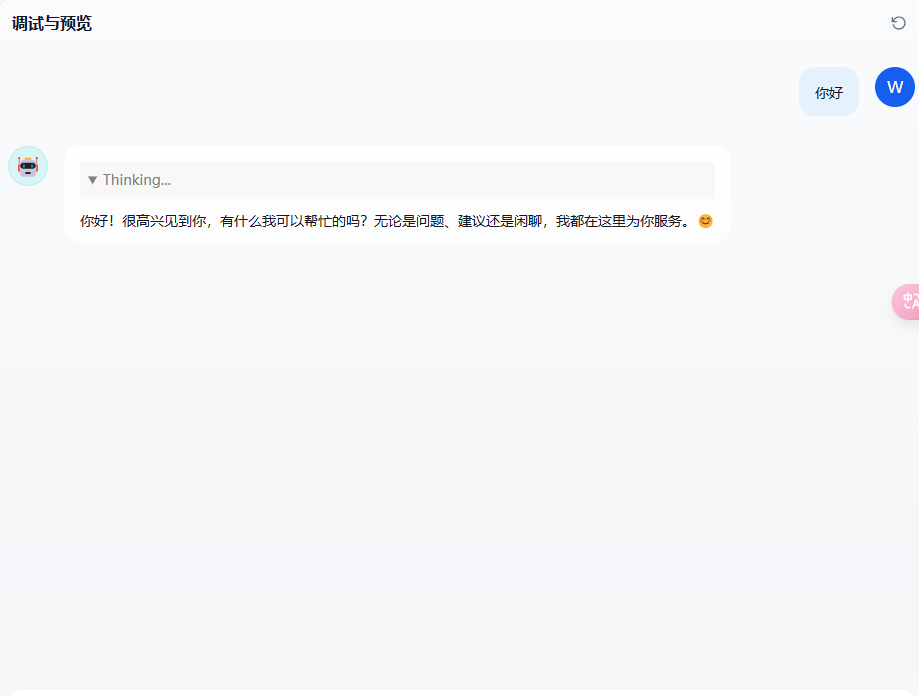
知识库
创建一个知识库
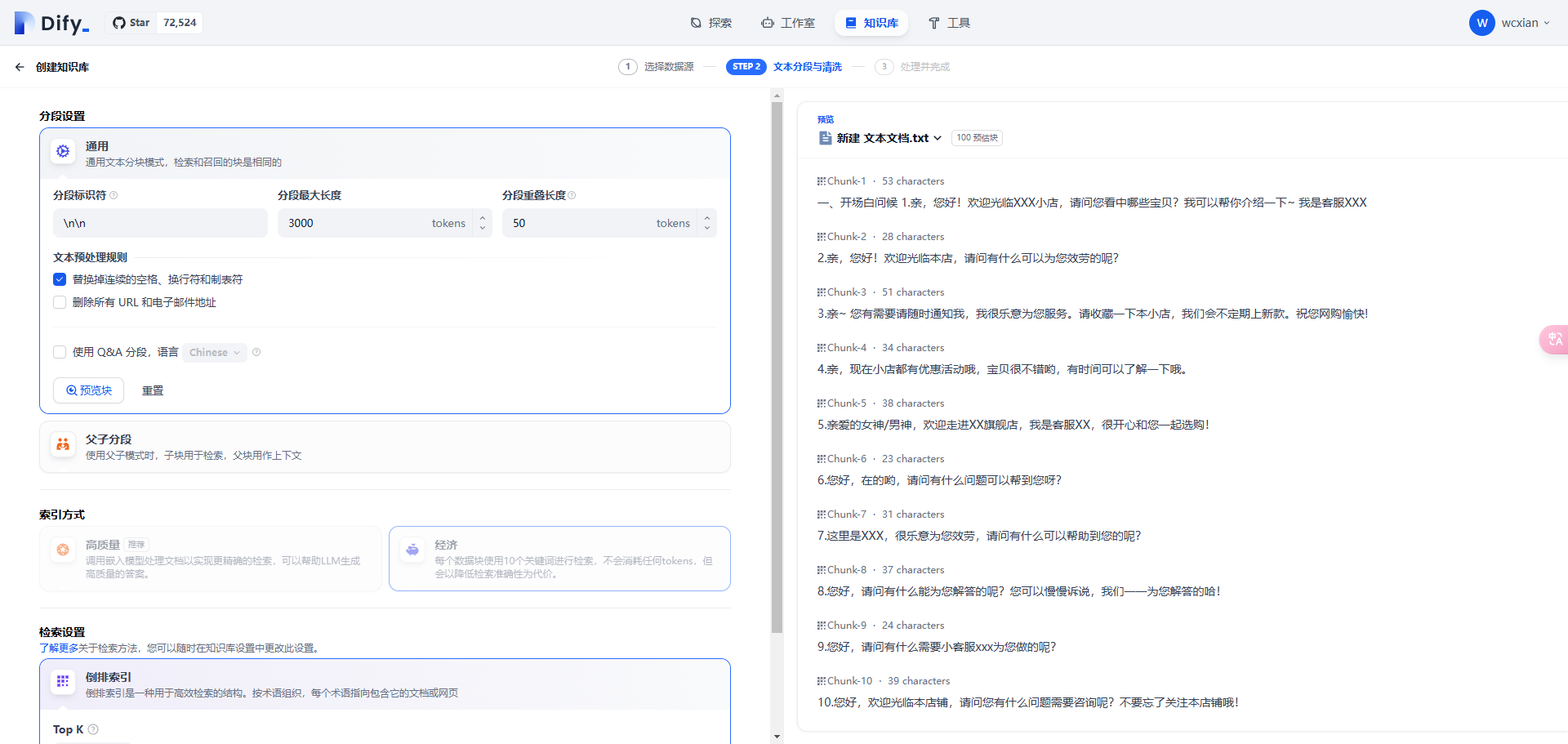
设置一下文本分析和清洗
因为我这边没有嵌入的模型,所以就用最简单的倒排索引,倒排索引就是之前es的那个
这边等待一段时间,模型就嵌入完了
然后可以在应用里添加上下文

在应用功能设置里设置一下
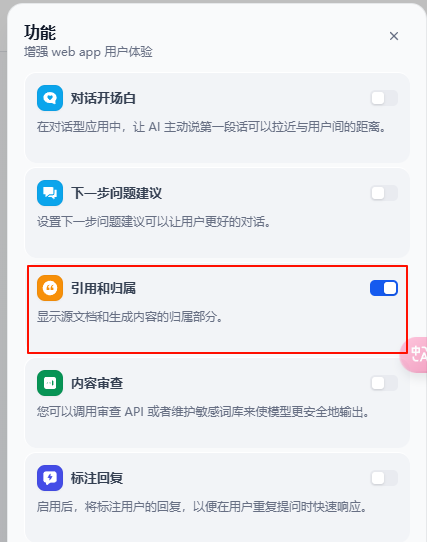
实验一下
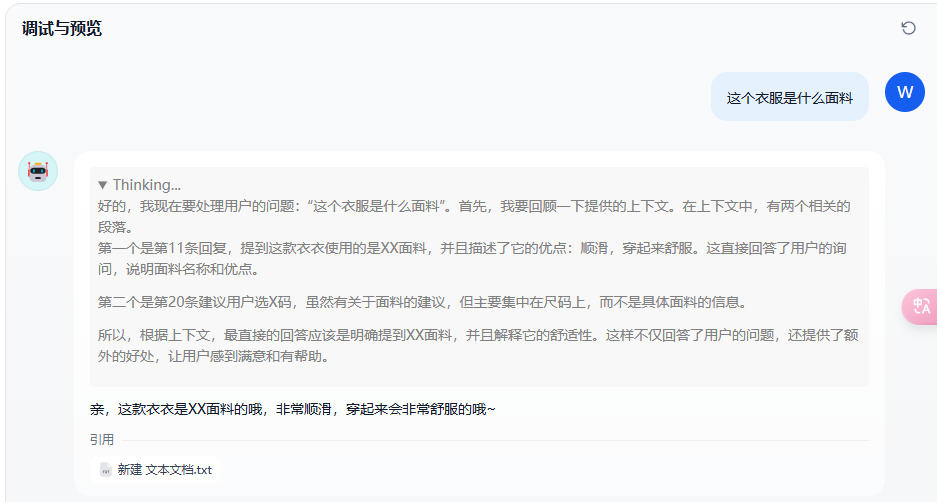
对比一下我的知识库,命中了11和20条

到这里,一个简单的知识库就搭建完了。
引用资料
超实用!用 Ollama + DeepSeek + Dify 搭建本地知识库,提升企业效率本文介绍了如何使用 Ollam - 掘金