
空色天绘/NEO TOKYO NOIR 03

5846 字
29 分钟
java导出excel

Java百万数据导出Excel
概述
用Java导出百万数据到excel中,需要注意一些事项
-
Excel 2007及以上版本(.xlsx),最大支持单Sheet 一百万(1048576)行,如果要在一个Excel文件中写入大于1百万行的数据,则需要每百万行创建一个Sheet
-
数据一般是从数据库中查出来的,如果一次查出太多数据内存可能装不下,需要分页查询*或流式查询导出。
在导出的数据量比较多的时候(分页查询有很多页)
-
是因为此代码写入时会阻塞下一页的查询,如果每次写入需要0.1秒,百万数据的导出,分页查询每页1万条,则有近10秒的时间浪费了;
-
查询性能通常数倍慢于写入速度,查询一般都经过网络,网络耗时+SQL执行耗时比较多,而写入一般是直接写入到本地磁盘中(或先写入本地临时文件,再通过IO流输出到HTTP响应中)
所以上述代码有两个性能优化的点
-
是读写分离,写入时不要影响到下一页的读
-
可以改为并发分页查询,减少因为写入太快而需要等待查询数据的时间;或改用流式查询。
代码实现
第一版:分页-先读后写版
使用:[easyexcel、mybatis-plus、java8+、lombok];
使用示例:
/** * 导出Excel(先查后写),<br> * 注意:实际应用中,pageSize参数不应对外开放,此处为方便测试,或pageSize需要设置上限,防止恶意用户传一个很大的pageSize值,而撑满内存 * @param response 响应 * @param pageSize 页大小 * @throws IOException */@GetMapping("/exportExcel")public void exportExcel(HttpServletResponse response, @RequestParam(value = "pageSize", defaultValue = "10000") int pageSize) throws IOException { XExcelUtil.download(response, "测试").pageSize(pageSize).pageExcelWriter(Demo.class, page -> demoService.lambdaQuery().page(page));}/** * 创建并初始化用于Excel文件下载的工具类实例 * 作用:配置HTTP响应头信息,指定Excel文件下载的相关参数(文件名、格式等) * * @param response HTTP响应对象,用于设置响应头信息(如文件名、内容类型) * @param fileNamePrefix 下载文件名的前缀(用户自定义部分,后续会拼接时间戳和文件后缀) * @return 初始化完成的XExcelUtil实例,可用于后续向Excel中填充数据 * @throws UnsupportedEncodingException 当URL编码过程中使用的UTF-8编码不被支持时抛出 */public static XExcelUtil download(HttpServletResponse response, String fileNamePrefix) throws UnsupportedEncodingException { // 创建Excel工具类实例,后续可用于填充数据、写入文件内容 XExcelUtil excelUtil = new XExcelUtil();
// 将HTTP响应对象绑定到工具类,便于后续通过工具类直接操作响应流 excelUtil.httpServletResponse = response;
// 构建完整文件名:前缀 + 当前时间戳 + .xlsx后缀 // xFormat("yyyyMMddHHmmss"):将时间格式化为"年月日时分秒"字符串,确保文件名唯一性 excelUtil.fileName = fileNamePrefix + "_" + Date.xNow().xFormat("yyyyMMddHHmmss") + ".xlsx";
// 设置响应内容类型:对应Excel 2007+格式(xlsx)的MIME类型 // MIME类型说明:application/vnd.openxmlformats-officedocument.spreadsheetml.sheet是Office Open XML格式的Excel文件标准MIME类型 response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
// 设置响应字符编码为UTF-8,确保文件名等中文内容正确显示 response.setCharacterEncoding("utf-8");
// 对文件名进行URL编码处理(解决中文文件名乱码问题) // 1. URLEncoder.encode:将文件名编码为UTF-8格式的URL安全字符串 // 2. replaceAll("\\+", "%20"):因为URLEncoder会将空格编码为"+",而HTTP标准中推荐用"%20"表示空格,此处替换确保兼容性 String downloadFileName = URLEncoder.encode(excelUtil.fileName, "UTF-8").replaceAll("\\+", "%20");
// 设置响应头Content-disposition:告知浏览器以附件形式下载文件 // filename*=utf-8'': 是RFC 5987标准的编码格式,明确指定文件名编码为UTF-8,解决中文文件名乱码问题 response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + downloadFileName);
// 返回初始化完成的XExcelUtil实例,调用方后续可使用该实例进行Excel内容的填充和写入 return excelUtil;}/** * 分页查询数据并写入Excel文件(支持自动分sheet页) * * @param outputStream Excel输出流(如HTTP响应流、文件输出流等) * @param fileName 文件名(用于日志记录,区分不同Excel任务) * @param head Excel表头对应的实体类Class(EasyExcel通过该类生成表头) * @param pageSize 每页查询的数据量 * @param pageFunction 分页查询函数(接收分页参数,返回查询结果页),通常用于数据库分页查询 * @param <T> Excel数据行对应的实体类泛型 */private static <T> void pageExcelWriter( OutputStream outputStream, String fileName, Class<T> head, long pageSize, UnaryOperator<IPage<T>> pageFunction) { long start = System.currentTimeMillis(); // 记录任务开始时间,用于统计总耗时 log.debug("fileName:{}, excel writer start", fileName); // 记录任务开始日志 // try-with-resources自动管理ExcelWriter资源,确保使用后关闭(避免内存泄漏) try (ExcelWriter excelWriter = EasyExcel.write(outputStream, head).build()) { IPage<T> page = null; // 分页查询结果对象,初始为null(表示首次查询) WriteSheet writeSheet = EasyExcel.writerSheet(0).build(); // 初始sheet(编号从0开始) // 循环分页查询并写入Excel,直到所有数据页处理完成 do { // 记录当前页查询开始时间,用于统计单页查询耗时 long pageSearchStartTime = System.currentTimeMillis();
// 根据是否为首次查询构造分页参数: // - 首次查询(page为null):创建第1页,每页大小pageSize // - 后续查询:当前页+1,保持页大小不变,复用总记录数(避免重复查询总条数,提升性能) page = pageFunction.apply( page == null ? new Page<>(1, pageSize) : // 首次查询:第1页,页大小pageSize new Page<>(page.getCurrent() + 1, page.getSize(), page.getTotal(), false) // 后续查询:下一页,禁用count查询 ); // 记录当前页数据写入开始时间,用于统计单页写入耗时 long pageExcelWriteStartTime = System.currentTimeMillis();
// 计算当前数据应写入的sheet编号: // 公式:(当前页号 * 每页大小) / 单sheet最大行数 → 确定当前累积记录数对应哪个sheet // (EXCEL_SHEET_ROW_MAX_SIZE为常量,如65535行,避免单sheet行数超Excel限制) writeSheet.setSheetNo((int) (page.getCurrent() * page.getSize() / EXCEL_SHEET_ROW_MAX_SIZE));
// 将当前页数据写入Excel的指定sheet excelWriter.write(page.getRecords(), writeSheet); // 打印当前页处理日志:包含文件名、总记录数、页大小、总页数、当前页号、sheet编号及耗时统计 log.debug( "fileName:{}, total:{}, pageSize:{}, totalPage:{}, pageNo:{}, sheetNo:{}, " + "pageSearchTime:{}ms, pageExcelWriterTime:{}ms", fileName, page.getTotal(), // 总记录数 page.getSize(), // 每页大小 page.getPages(), // 总页数 page.getCurrent(), // 当前页码 writeSheet.getSheetNo(), // 当前写入的sheet编号 pageExcelWriteStartTime - pageSearchStartTime, // 当前页查询耗时(ms) System.currentTimeMillis() - pageExcelWriteStartTime // 当前页写入耗时(ms) ); } while (page.getCurrent() < page.getPages()); // 循环条件:当前页码 < 总页数(是否还有下一页) } // ExcelWriter在try-with-resources结束时自动关闭,释放资源 // 记录任务总耗时日志 log.debug( "fileName:{}, excel writer done, totalTime:{}ms", fileName, System.currentTimeMillis() - start );}关键逻辑说明
- 分页查询优化:
- 首次查询创建第1页,后续查询通过
page.getCurrent() + 1获取下一页,避免重复计算总页数。 - 非首次查询时,构造
Page对象传入page.getTotal()并设置false,禁用重复查询总记录数(count语句),提升性能。
- 首次查询创建第1页,后续查询通过
- 分sheet写入机制:
通过
(page.getCurrent() * page.getSize() / EXCEL_SHEET_ROW_MAX_SIZE)计算当前应写入的sheet编号。假设EXCEL_SHEET_ROW_MAX_SIZE为1000(Excel单sheet最大行数限制),当累积记录数超过1000行时,自动切换到新sheet(编号递增),避免单sheet行数超限导致Excel错误。 - 资源安全:
使用
try-with-resources管理ExcelWriter,确保无论是否发生异常,资源都会被正确关闭,避免内存泄漏。 - 性能监控: 记录了总任务耗时、单页查询耗时、单页写入耗时等日志,便于问题排查和性能优化。
日志输出:
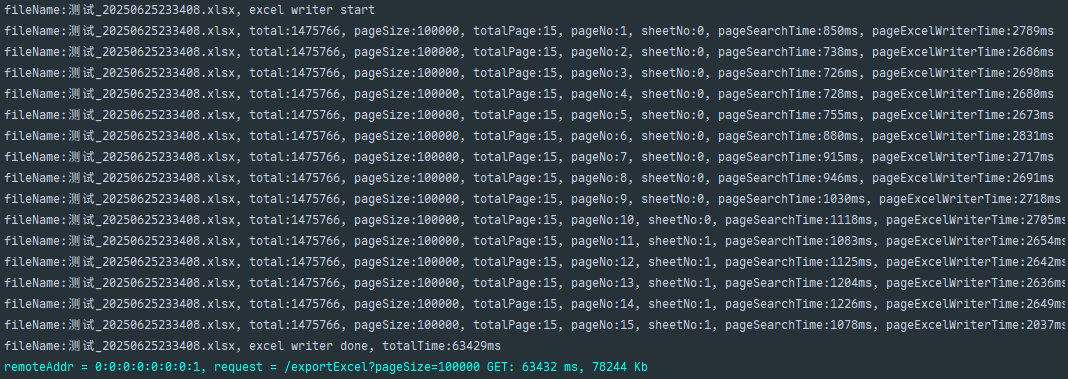
先读后写版(查询和写入用时差距不大是因为读写在同一台电脑上)(MySQL)
第二版:读写分离版(并发读)
使用:[阻塞队列,线程池],[easyexcel、mybatis-plus、java8+、lombok]
通过定义一个阻塞队列,在主线程中新起一个线程用于查询([并发]查询时将查询结果放入队列中),写入时直接从队列中进行获取待写入数据,实现读写分离和降低写入时等待查询数据的时间,从而降低总体用时。
使用示例:
/** * 导出Excel[下载速度可能更快](并发查询,串行写入)<br> * 注意:实际应用中,pageSize和parallelNum参数不应对外开放,此处为方便测试,或pageSize需要设置上限,防止恶意用户传一个很大的pageSize值,而撑满内存。 * @param response 响应 * @param parallelNum 并发查询线程数 * @param pageSize 页大小 * @throws IOException */@GetMapping("/writeExcelForXParallel")public void writeExcelForXParallel(HttpServletResponse response, @RequestParam(value = "parallelNum", defaultValue = "3") int parallelNum, @RequestParam(value = "pageSize", defaultValue = "10000") int pageSize) throws IOException { XExcelUtil.download(response, "测试并发查询导出").parallel(parallelNum).pageSize(pageSize).pageExcelWriter(Demo.class, page -> demoService.lambdaQuery().page(page));}/** * 并行分页查询并写入Excel文件(支持自动分Sheet) * * @param <T> Excel数据行对应的Java实体类类型(泛型) * @param outputStream Excel文件的输出流(如网络响应流、本地文件流等) * @param fileName 文件名(用于日志打印,标识当前处理的文件) * @param head Excel表头对应的实体类Class(EasyExcel据此解析表头信息) * @param parallelNum 并行处理数量(控制同时执行的查询/写入任务数) * @param pageSize 每页查询的数据量大小(单次查询获取的数据条数) * @param pageFunction 分页查询函数(用户自定义的分页数据获取逻辑,如从数据库查数据) * @throws ExecutionException 并行处理中可能抛出的异常(如任务执行失败) * @throws InterruptedException 并行处理被中断时抛出的异常 */private static <T> void pageExcelWriterParallel( OutputStream outputStream, String fileName, Class<T> head, int parallelNum, long pageSize, UnaryOperator<IPage<T>> pageFunction) throws ExecutionException, InterruptedException { // 记录开始时间,用于统计总耗时 long start = System.currentTimeMillis(); log.debug("fileName:{}, excel writer start", fileName); // 使用try-with-resources自动管理ExcelWriter资源,确保最终关闭流释放资源 try (ExcelWriter excelWriter = EasyExcel.write(outputStream, head).build()) { // 创建初始Sheet(默认第0个Sheet,名称为"Sheet0") final WriteSheet writeSheet = EasyExcel.writerSheet(0, "Sheet0").build(); // 1. 初始化基础分页参数(获取总记录数并设置分页大小) // 注:先调用pageFunction查询第1页、size=0的数据,目的是获取总记录数(total) // 然后通过setSize(pageSize)设置实际分页大小,从而计算总页数 IPage<T> basePage = pageFunction.apply(new Page<>(1, 0)) // 查总记录数(size=0表示仅获取总数,不返回数据) .setSize(pageSize); // 设置实际分页大小,计算总页数 log.debug("fileName:{}, 分页查询初始化完成,总记录数:{}, 每页条数:{}, 总页数:{}", fileName, basePage.getTotal(), basePage.getSize(), basePage.getPages()); // 2. 通过SlidingWindow实现并行处理:多线程并行查询分页数据并写入Excel // SlidingWindow是一个并行处理工具,用于控制并行任务的发送(查询)和接收(写入) SlidingWindow.<IPage<T>>create( new TypeReference<IPage<T>>(){}, // 泛型类型引用(指定窗口处理的数据类型) parallelNum, // 并行处理数量(同时执行的任务数) basePage.getPages() // 总任务数(等于总页数,即需要查询的页数) ) // 发送窗口:定义如何并行获取分页数据(并行执行查询任务) .sendWindow(pageNo -> { // pageNo:当前处理的页码(从1开始) long pageSearchStartTime = System.currentTimeMillis(); // 调用用户提供的pageFunction查询指定页码的数据 // Page参数:current=pageNo(当前页码),size=pageSize(每页条数) IPage<T> page = pageFunction.apply(new Page<>(pageNo, basePage.getSize())); log.debug("fileName:{}, [读]pageNo:{}, total:{}, pageSize:{}, pageSearchTime:{}ms", fileName, pageNo, page.getTotal(), page.getSize(), System.currentTimeMillis() - pageSearchStartTime); return page; // 将查询到的分页数据传递给接收窗口处理 }) // 接收窗口:定义如何处理查询到的分页数据(并行执行写Excel任务) .receiveWindow(page -> { // page:sendWindow返回的分页数据 long pageWriteStartTime = System.currentTimeMillis(); // TODO: 假设EXCEL_SHEET_ROW_MAX_SIZE是类中定义的常量(如Excel单个Sheet最大行数限制,如65535) // 计算当前页数据应写入的Sheet编号(通过累计记录数/单Sheet最大行数) // 累计记录数 = (页码-1)*pageSize + 当前页记录数(这里简化为 pageNo * pageSize,需根据实际逻辑确认) long cumulativeRecords = (page.getCurrent() - 1) * page.getSize() + page.getRecords().size(); int sheetNo = (int) (cumulativeRecords / EXCEL_SHEET_ROW_MAX_SIZE); // 计算Sheet编号(从0开始) writeSheet.setSheetNo(sheetNo); // 设置当前写入的Sheet编号 writeSheet.setSheetName("Sheet" + sheetNo); // 设置Sheet名称 // 将当前分页数据写入Excel的指定Sheet excelWriter.write(page.getRecords(), writeSheet);
log.debug("fileName:{}, [写]pageNo:{}, sheetNo:{}, pageWriteTime:{}ms", fileName, page.getCurrent(), sheetNo, System.currentTimeMillis() - pageWriteStartTime); }) // 启动并行处理流程 .start(); } // ExcelWriter会在此处自动关闭,释放资源 // 记录任务总耗时 log.debug("fileName:{}, excel writer done, totalTime:{}ms", fileName, System.currentTimeMillis() - start);}关键逻辑说明
- 核心功能: 该方法通过并行查询分页数据并写入Excel,解决大数据量下Excel生成效率问题。利用SlidingWindow实现并行查询与写入,同时根据数据量自动拆分多个Sheet,避免单个Sheet行数超限(如Excel的65535行限制)。
- SlidingWindow滑动窗口机制:
- create:初始化滑动窗口,指定处理的数据类型、并行数量(
parallelNum)和总任务数(总页数)。 - sendWindow:定义如何生成并行任务——对每一页数据发起并行查询(通过
pageFunction),pageNo是当前处理的页码。 - receiveWindow:定义如何处理查询结果——将查询到的分页数据写入Excel,并根据累计记录数计算目标Sheet编号,实现数据分片写入多个Sheet。
- start():启动并行处理流程,开始执行查询和写入任务。
- create:初始化滑动窗口,指定处理的数据类型、并行数量(
- 分页查询与总页数计算:
- first调用
pageFunction.apply(new Page<>(1, 0))时,通过size=0的分页参数,仅获取总记录数(total),不返回实际数据,用于后续计算总页数。 - 通过
basePage.setSize(pageSize)设置实际分页大小后,MyBatis-Plus的IPage会自动计算总页数(pages = total / pageSize,向上取整)。
- first调用
- 分Sheet逻辑:
通过累计记录数(
(pageNo-1)*pageSize + 当前页记录数)除以单个Sheet允许的最大行数(EXCEL_SHEET_ROW_MAX_SIZE),动态计算当前数据应写入的Sheet编号,避免单个Sheet行数过多导致Excel异常。 - 资源管理与性能优化:
- 使用
try-with-resources管理ExcelWriter,确保流资源自动关闭,避免内存泄漏。 - 详细的日志记录(包括总耗时、查询耗时、写入耗时)便于性能瓶颈定位和优化。
- 并行处理(
parallelNum控制线程数)提高数据查询和写入效率,但需注意控制并行数避免资源耗尽。
- 使用
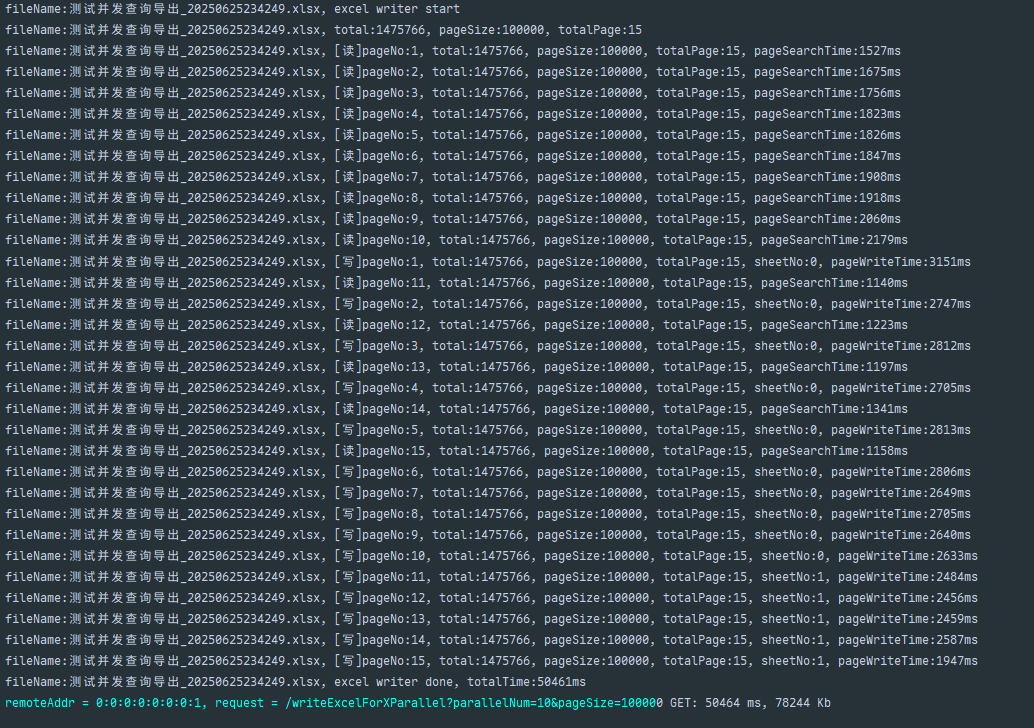
第三版:并行写入
移除mybatis-plus、lombok依赖
/** * 导出Excel(并发查询,串行写入)<br> * 注意:实际应用中,pageSize和parallelNum参数不应对外开放,此处为方便测试,或pageSize需要设置上限,防止恶意用户传一个很大的pageSize值,而撑满内存。 * @param response 响应 * @param parallelNum 并发查询线程数 * @param pageSize 页大小 * @throws IOException * @throws InterruptedException */@GetMapping("/writeExcelForParallel")public void writeExcelForParallel(HttpServletResponse response, @RequestParam(value = "parallelNum", defaultValue = "3") int parallelNum, @RequestParam(value = "pageSize", defaultValue = "10000") int pageSize) throws IOException, InterruptedException { LambdaQueryWrapper<Demo> queryWrapper = Wrappers.lambdaQuery(Demo.class); demoService.writeExcelForParallel(excelOutput(response, "测试"), parallelNum, pageSize, queryWrapper);/** * 核心并行Excel写入实现(私有工具方法) * <p>使用并行方式查询数据页并写入Excel,支持自动分sheet(当单sheet行数超限)</p> * @param excelWriter EasyExcel的写入器对象(负责Excel文件生成) * @param parallelNum 并行处理线程数 * @param totalPage 总页数(需查询的数据总页数) * @param pageListFunction 函数式接口:根据页码获取对应页数据列表 * @param <T> 数据实体类型 * @throws InterruptedException 当并行处理被中断时抛出 */private static <T> void pageExcelWriterParallel(ExcelWriter excelWriter, int parallelNum, long totalPage, LongFunction<List<T>> pageListFunction) throws InterruptedException { // try-with-resources自动关闭excelWriter,确保资源释放(无论是否发生异常) try (excelWriter) { // 1. 无数据时(总页数<=0),写入空数据(仅保留表头) if (totalPage <= 0) { excelWriter.write(Collections.emptyList(), EasyExcel.writerSheet().build()); return; } // 2. 初始化计数器和Sheet配置 AtomicLong count = new AtomicLong(); // 累计写入记录数,用于分sheet判断 WriteSheet writeSheet = EasyExcel.writerSheet(1, "Sheet1").build(); // 初始sheet配置(序号1,名称"Sheet1") // 3. 并行处理数据查询与写入 // ParallelUtil.parallel:创建并行任务(指定泛型类型、并行数、总页数) // asyncProducer:异步生产者,根据页码并行查询数据页(线程安全的多线程查询) // syncConsumer:同步消费者,按顺序写入数据到Excel(避免并发写入冲突) ParallelUtil.parallel(new TypeReference<List<T>>(){}, parallelNum, totalPage) .asyncProducer(pageListFunction) // 异步生产数据:调用pageListFunction获取指定页数据 .syncConsumer(pageList -> { // 同步消费数据:将数据写入Excel // 计算当前累计写入记录数,动态调整sheet long currentCount = count.addAndGet(pageList.size()); // EXCEL_SHEET_ROW_MAX_SIZE为常量(如Excel默认单sheet最大65536行),超过则创建新sheet int sheetNo = (int) (currentCount / EXCEL_SHEET_ROW_MAX_SIZE + 1); writeSheet.setSheetNo(sheetNo); writeSheet.setSheetName("Sheet" + sheetNo); // 将当前数据页写入指定sheet excelWriter.write(pageList, writeSheet); }).start(); // 启动并行任务 }}关键逻辑说明
- 分层设计:
writeExcelForParallel:业务层方法,对接业务逻辑,负责查询总页数并调用工具类。writeForParallel:工具层方法,负责构建Excel写入器(配置表头、样式)并转发至核心实现。pageExcelWriterParallel:核心实现层,使用并行工具处理数据查询与写入,支持多sheet切换。
- 关键技术点:
- 分页查询优化:首次查询
size=0仅获取总条数,避免无用数据查询。 - 并行处理:通过
ParallelUtil实现数据页的并行查询(生产者)和顺序写入(消费者),提高效率的同时保证写入顺序。 - 动态分sheet:通过累计写入记录数自动判断是否超限,超过则创建新sheet(如
Sheet1、Sheet2…)。 - 资源安全:使用try-with-resources自动管理
ExcelWriter资源,确保流关闭和内存释放。
- 分页查询优化:首次查询
- 核心优势:
- 性能优化:并行查询数据提高效率,尤其适合大数据量导出。
- 自动化:自动分sheet避免单个sheet行数超限问题(Excel格式限制)。
- 易用性:业务层只需关注查询条件,无需关心Excel写入细节。

第四版:流式查询导出
/** * 导出Excel(流式查询) * @param response 响应 * @throws IOException */@GetMapping("/writeExcelForFetch")public void writeExcelForFetch(HttpServletResponse response) throws IOException { LambdaQueryWrapper<Demo> queryWrapper = Wrappers.lambdaQuery(Demo.class); demoService.writeExcelForFetch(excelOutput(response, "测试"), queryWrapper);}/** * 分页查询数据并写入Excel输出流(支持大数据量自动分Sheet) * @param outputStream 输出流(目标Excel文件的输出载体,如HTTP响应流或文件流) * @param queryWrapper 查询条件包装器(指定数据筛选条件,如MyBatis-Plus的查询条件) */public void writeExcelForFetch(OutputStream outputStream, Wrapper<T> queryWrapper) { // 1. try-with-resources创建ExcelWriter,自动关闭资源(避免内存泄漏) try (ExcelWriter excelWriter = EasyExcel .write(outputStream, getEntityClass()) // 指定输出流和数据实体类型(用于自动映射Excel表头) .registerWriteHandler(new LongestMatchColumnWidthStyleStrategy()) // 注册列宽自适应策略 .build()) { // 构建Excel写入器
// 2. 创建初始Sheet对象(初始Sheet编号未明确指定,后续动态调整) WriteSheet writeSheet = EasyExcel.writerSheet().build(); // 默认从第一个Sheet开始
// 3. 分页查询数据并写入Excel:通过pageForFetch方法实现分页流式查询+分批写入 long totalPage = pageForFetch(queryWrapper, page -> { // page是当前分页数据对象(IPage) // 核心逻辑1:计算当前批次数据应写入的Sheet编号 // 公式:(当前页码 * 每页条数) / 单个Sheet最大行数 + 1(Sheet编号从1开始) int sheetNo = (int) (page.getCurrent() * page.getSize() / EXCEL_SHEET_ROW_MAX_SIZE + 1); writeSheet.setSheetNo(sheetNo); // 更新当前写入的Sheet编号 writeSheet.setSheetName("Sheet" + sheetNo); // 设置Sheet名称(如Sheet1、Sheet2)
// 核心逻辑2:将当前分页数据写入指定Sheet excelWriter.write(page.getRecords(), writeSheet); // 写入当前页数据到Excel log.debug("写入进度:总条数={}, 每页大小={}, 总页数={}, 当前页={}, 当前Sheet={}", page.getTotal(), page.getSize(), page.getPages(), page.getCurrent(), sheetNo); });
// 4. 边界处理:若无数据(totalPage <= 0),仍写入空Sheet(仅含标题行,避免Excel文件损坏) if (totalPage <= 0) { excelWriter.write(Collections.emptyList(), EasyExcel.writerSheet().build()); // 写入空Sheet(仅标题) } } // 5. try-with-resources自动关闭ExcelWriter,释放资源}
/** * 分页流式查询数据并按批次回调处理(适用于大数据量导出,避免内存溢出) * * @param wrapper 查询条件包装器(如MyBatis-Plus的查询条件构造器) * @param pageConsumer 分页数据处理器(回调函数,用于处理每一批分页数据) * @return 总页数(根据总记录数和批次大小计算得出) */public long pageForFetch(Wrapper<T> wrapper, Consumer<IPage<T>> pageConsumer) { // 步骤1:先查询总记录数(仅查总数,不查具体数据) // 创建一个页码为1、每页0条数据的Page对象,目的是触发COUNT查询获取总记录数 IPage<T> page = page(new Page<>(1, 0), wrapper); // XXX 查总条数
// 步骤2:设置实际分页查询的每页大小(FETCH_SIZE为自定义常量,如1000条/页) page.setSize(FETCH_SIZE);
// 步骤3:初始化页码计数器(原子类确保线程安全的自增操作,即使在多线程环境下也不会出错) AtomicLong pageNo = new AtomicLong();
// 步骤4:创建临时列表缓存当前批次数据,初始容量为每页大小(避免频繁扩容) List<T> tmpList = new ArrayList<>((int) page.getSize());
// 步骤5:流式查询数据并分批处理(核心逻辑) // selectList方法的重载版本:接收ResultContext回调,逐条处理查询结果(避免一次性加载全部数据到内存) baseMapper.selectList(wrapper, resultContext -> { // 将当前遍历到的单条记录加入临时列表 tmpList.add(resultContext.getResultObject());
// 当临时列表中的记录数达到每页大小时(即凑满一个批次): if (resultContext.getResultCount() % page.getSize() == 0) { // 页码自增(从0开始,首次处理后变为1) page.setCurrent(pageNo.incrementAndGet()); // 将当前批次记录设置到page对象中,并通过回调函数处理该批次数据 pageConsumer.accept(page.setRecords(tmpList)); // 清空临时列表,准备接收下一批数据 tmpList.clear(); } });
// 步骤6:处理最后一批不足一页的数据(若临时列表中仍有剩余数据未处理) if (!tmpList.isEmpty()) { page.setCurrent(pageNo.incrementAndGet()); // 页码自增(处理最后一页) pageConsumer.accept(page.setRecords(tmpList)); // 回调处理最后一批数据 tmpList.clear(); // 清空缓存,释放内存 }
// 返回总页数(根据总记录数和每页大小计算得出,即 page.getPages()) return page.getPages();}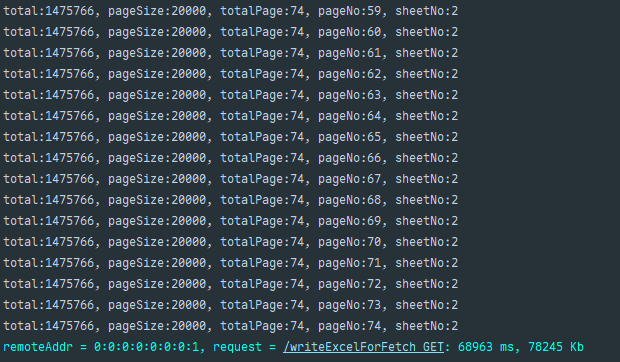
另一个思路:打成zip包
/** * 多线程批量导出 excel * * @param response 用于浏览器下载 * @throws InterruptedException */public void threadExcel(HttpServletResponse response) { long start = System.currentTimeMillis(); initQueue(); //异步转同步,等待所有线程都执行完毕返回 主线程才会结束 try { Queue<Map<String, Object>> queue = queueThreadLocal.get(); CountDownLatch cdl = new CountDownLatch(queue.size()); while (queue.size() > 0) { asynExportExcelService.excuteAsyncTask(queue.poll(), cdl); } cdl.await(); log.info("excel导出完成·······················"); //压缩文件 File zipFile = new File(filePath.substring(0, filePath.length() - 1) + ".zip"); FileOutputStream fos1 = new FileOutputStream(zipFile); //压缩文件目录 ZipUtils.toZip(filePath, fos1, true); //发送zip包 ZipUtils.sendZip(response, zipFile); } catch (Exception e) { log.error("excel导出异常", e); } finally { // 使用完ThreadLocal对象之后清除数据,防止内存泄露 queueThreadLocal.remove(); } long end = System.currentTimeMillis(); log.info("任务执行完毕共消耗: " + (end - start) + "ms");}@Async("taskExecutor")public void excuteAsyncTask(Map<String, Object> map, CountDownLatch cdl) { long start = System.currentTimeMillis(); int currentPage = (int) map.get("page"); int pageSize = (int) map.get("limit"); List<KjGoods> list = kjGoodsMapper.selectList(new QueryWrapper<>()); List subList = new ArrayList(page(list, pageSize, currentPage)); int count = subList.size(); System.out.println("线程:" + Thread.currentThread().getName() + " , 读取数据,耗时 :" + (System.currentTimeMillis() - start) + "ms"); StringBuilder filePath = new StringBuilder(map.get("path").toString()); filePath.append("线程").append(Thread.currentThread().getName()).append("-") .append("页码").append(map.get("page")).append(".xlsx"); // 调用导出的文件方法 Workbook workbook = MyExcelExportUtil.getWorkbook("商品数据", "商品", KjGoods.class, subList, ExcelType.XSSF); File file = new File(filePath.toString()); MyExcelExportUtil.exportExcel2(workbook, file); long end = System.currentTimeMillis(); System.out.println("线程:" + Thread.currentThread().getName() + " , 导出excel" + map.get("page") + ".xlsx成功 , 导出数据:" + count + " ,耗时 :" + (end - start) + "ms"); // 执行完线程数减1 cdl.countDown(); System.out.println("剩余任务数 ===========================> " + cdl.getCount());}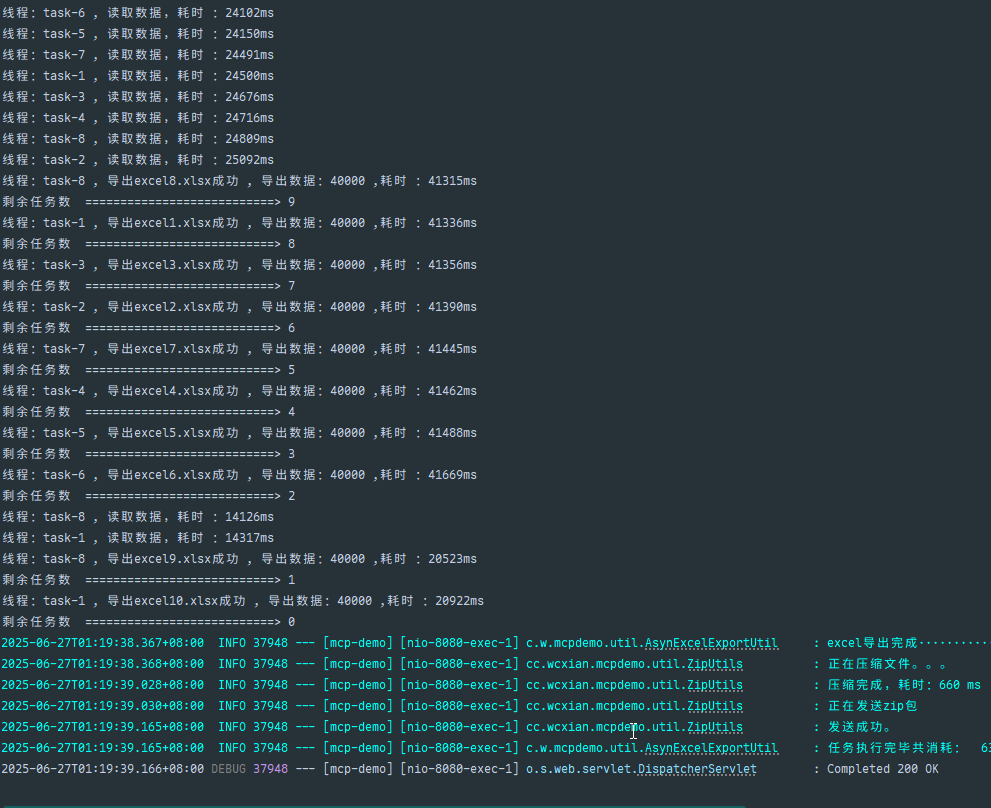
Java百万数据导出Excel性能优化[读(并发)写分离/流式查询]
java导出excel
https://fuwari.vercel.app/posts/java导出excel/