


PostgreSQL
概述
核心理念
- 一个数据库满足所有需求:对于业务量不大的中小系统,仅仅一个PostgreSQL就能替代多种复杂组件
- 开源免费:完全开源,功能扩展极其强大
- 设计理念先进:对象+关系型数据库,支持多种数据类型和扩展
1:PostgreSQL简介
什么是PostgreSQL?
- 世界上最先进的开源关系型数据库
- 对象-关系型数据库系统(ORDBMS)
- 支持复杂查询、外键、触发器、视图等
- 可扩展性强,支持自定义函数、数据类型、索引方法
核心优势
- 功能丰富:支持JSON、GIS、全文搜索等多种数据类型
- ACID兼容:完全符合事务ACID特性
- 并发控制:MVCC(多版本并发控制)
- 扩展性强:支持各种插件和扩展
- 开源免费:无授权费用,社区活跃
2:安装配置
2.1 Windows安装
PostgreSQL Windows安装流程
EDB: Open-Source, Enterprise Postgres Database Management
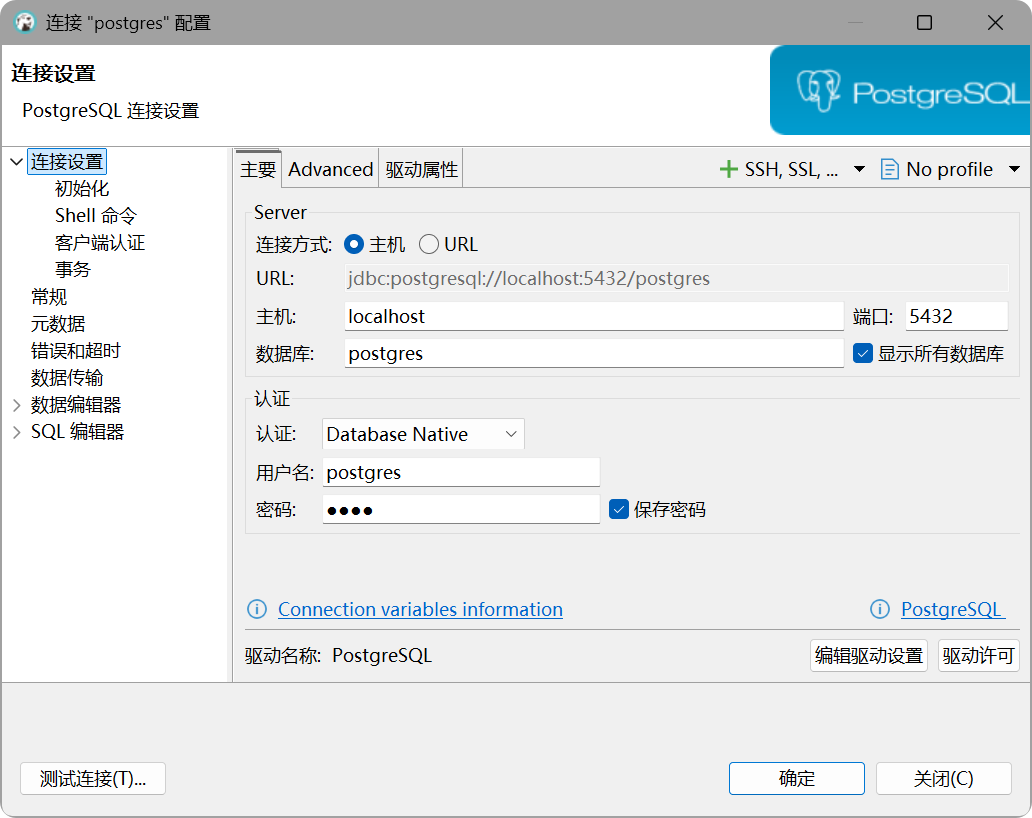
2.2 连接
端口:5432
初始用户名:postgres
初始密码:root
我这边使用DBeaver,对postgresql支持比较好
3:对象+关系特性
理解了“对象”和“关系”这两个概念,就理解了为什么 PostgreSQL 被称为“对象-关系型数据库”。
- 关系:是传统关系型数据库的基础。它代表着结构化、可预测、原子性的数据,通过表格来存储,并用主外键建立连接。这是 PostgreSQL 的根基。
- 对象:是 PostgreSQL 在“关系”基础上的重大扩展。它代表着复杂、结构化、可自定义的数据实体,允许你将数据和操作这些数据的行为封装在一起。这是 PostgreSQL 强大和灵活的源泉。
3.1 复合类型(Composite Types)
-- 创建地址复合类型CREATE TYPE address AS ( street VARCHAR(100), city VARCHAR(50), state VARCHAR(50), postal_code VARCHAR(20));
-- 创建用户表使用复合类型CREATE TABLE users ( id SERIAL PRIMARY KEY, name VARCHAR(100), home_address address, work_address address);
-- 插入数据INSERT INTO users (name, home_address)VALUES ('张三', ('中山路123号', '北京', '北京', '100000'));
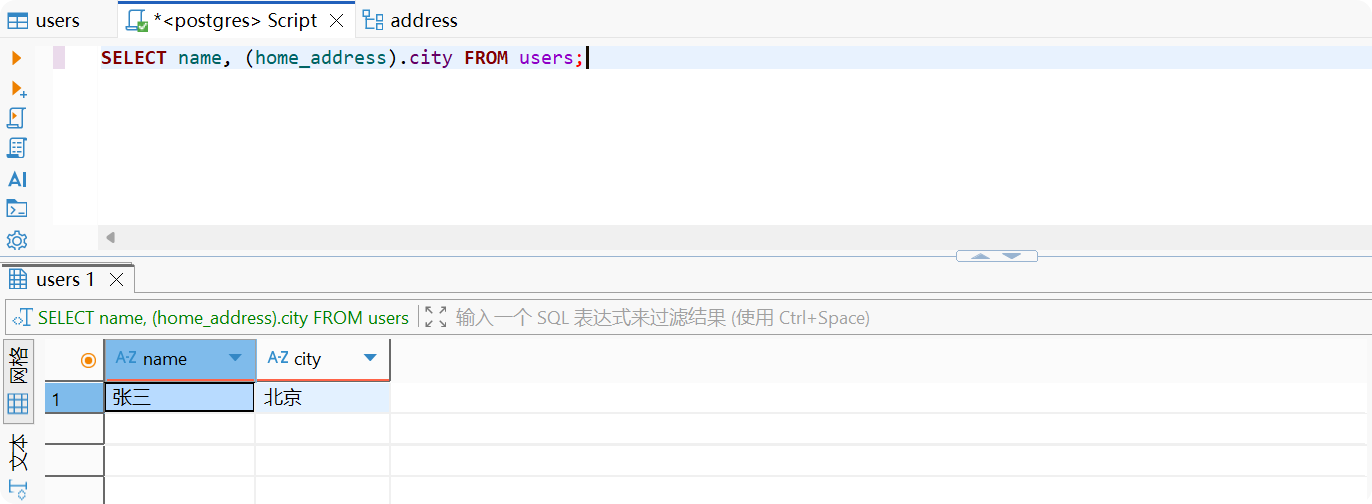
-- 查询复合类型字段SELECT name, (home_address).city FROM users;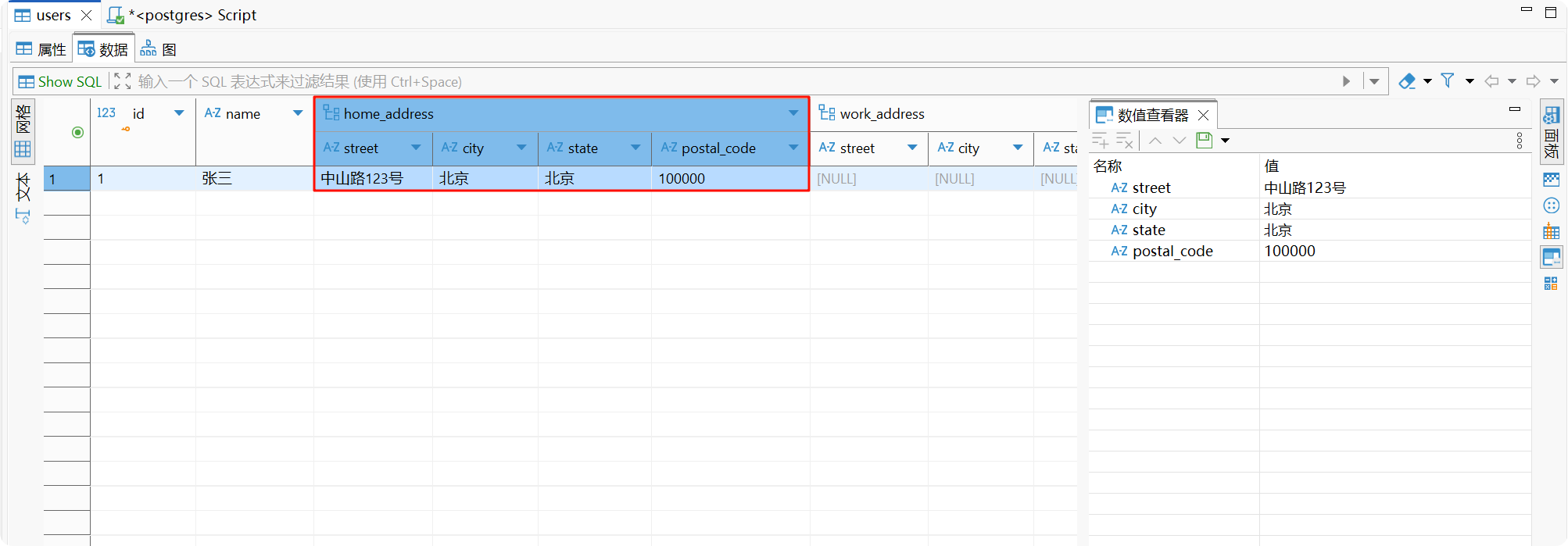
3.2 继承(Table Inheritance)
-- 创建基础表-- 员工表CREATE TABLE employees ( id SERIAL PRIMARY KEY, name VARCHAR(100), email VARCHAR(100));
-- 创建继承表-- 公司管理表CREATE TABLE managers ( department VARCHAR(50), level INTEGER) INHERITS (employees);-- 公司开发表CREATE TABLE developers ( programming_language VARCHAR(50), years_experience INTEGER) INHERITS (employees);
-- 插入数据INSERT INTO employees (name, email)
INSERT INTO managers (name, email, department, level)
INSERT INTO developers (name, email, programming_language, years_experience)
-- 查询所有员工SELECT * FROM employees;-- 查询特定类型员工SELECT * FROM ONLY employees;查询员工(包括所有类型的员工)
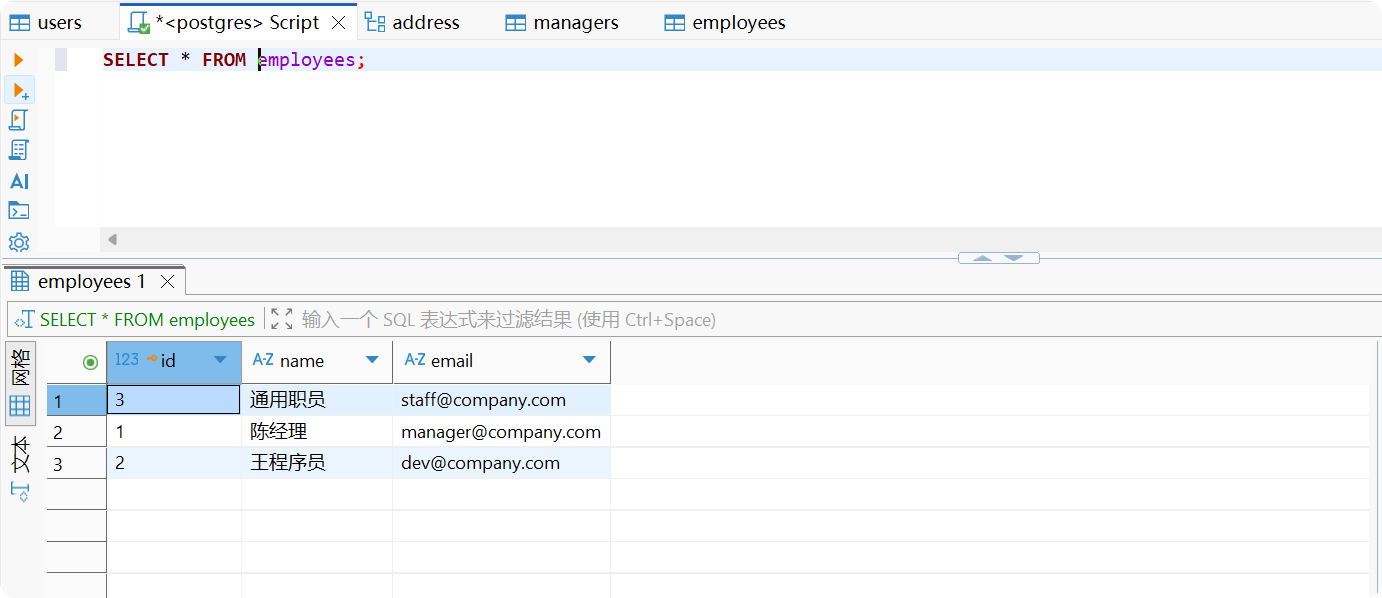
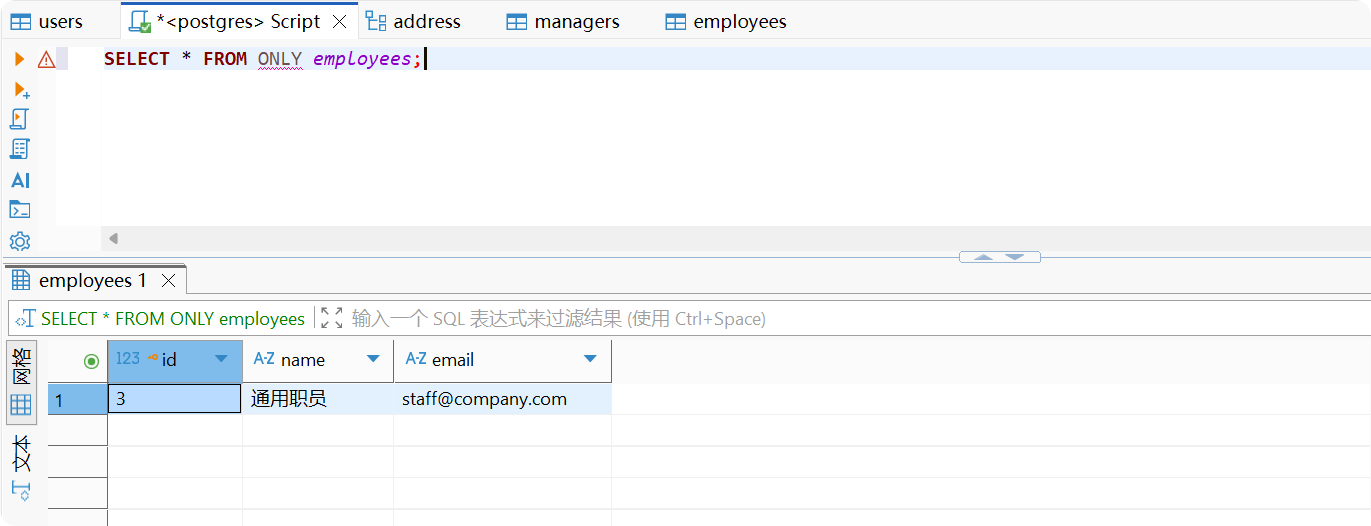
只查询父表中的基础员工
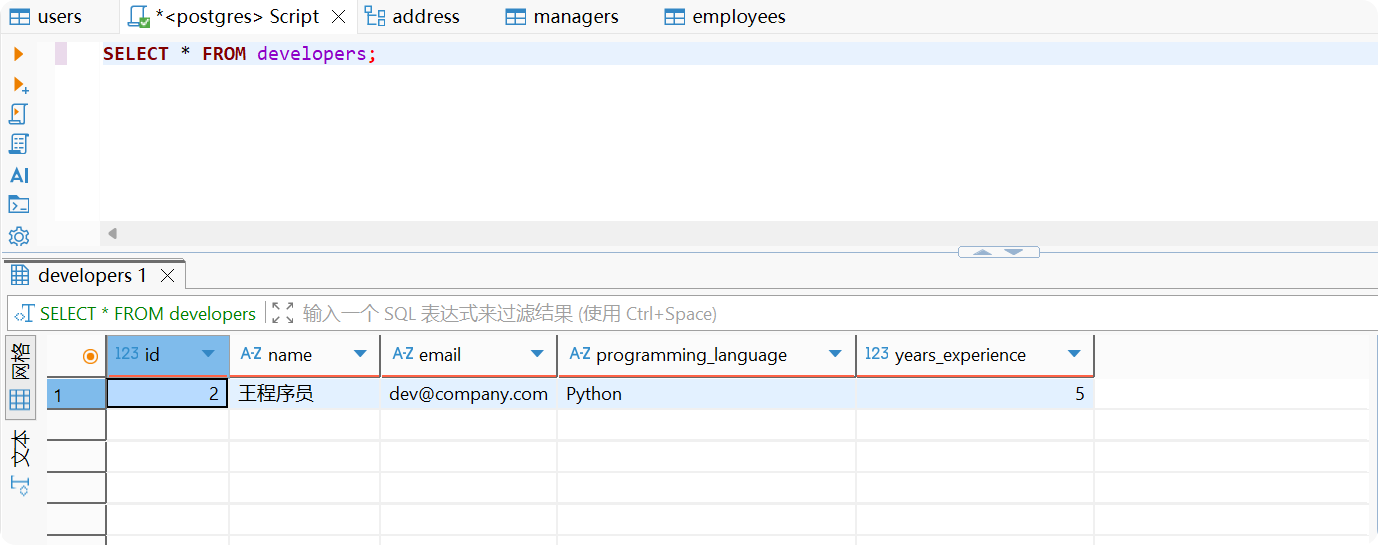
只查询开发者
3.3 数组类型(Arrays)
-- 创建包含数组的表CREATE TABLE products ( id SERIAL PRIMARY KEY, name VARCHAR(100), tags TEXT[], price_history DECIMAL(10,2)[]);
-- 插入数组数据INSERT INTO products (name, tags, price_history)VALUES ('智能手机', ARRAY['电子产品', '通讯', '生活用品'], ARRAY[2999.00, 2899.00, 2799.00]);
-- 查询包含特定标签的产品SELECT * FROM products WHERE '电子产品' = ANY(tags);
-- 获取数组长度SELECT name, array_length(tags, 1) FROM products;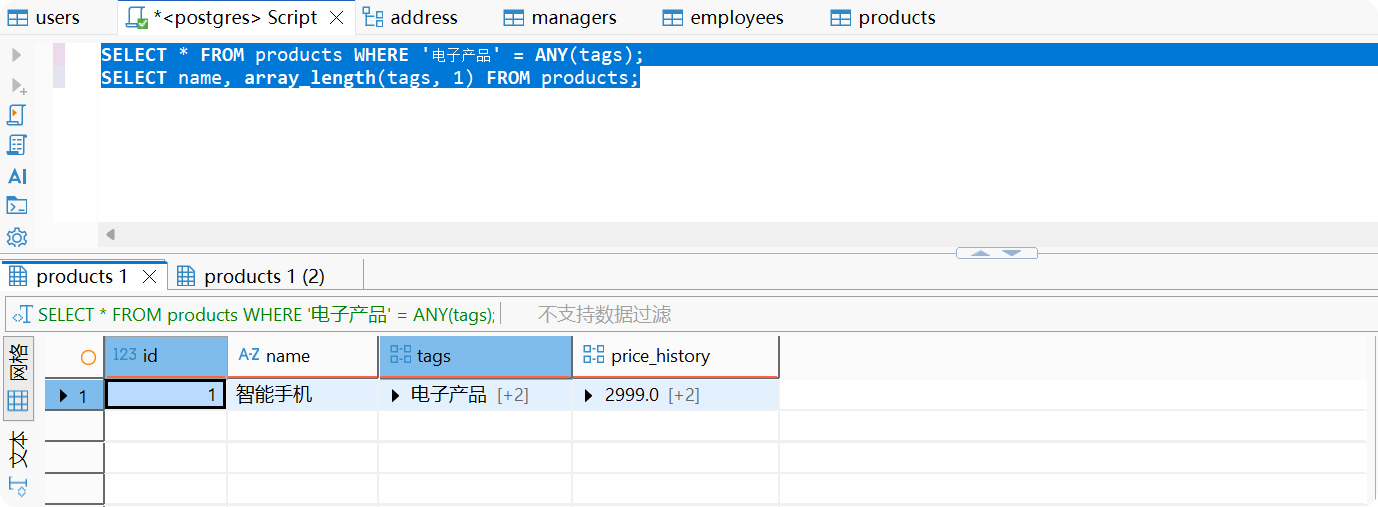
4:替换MongoDB - JSON/JSONB支持
4.1 JSONB数据类型
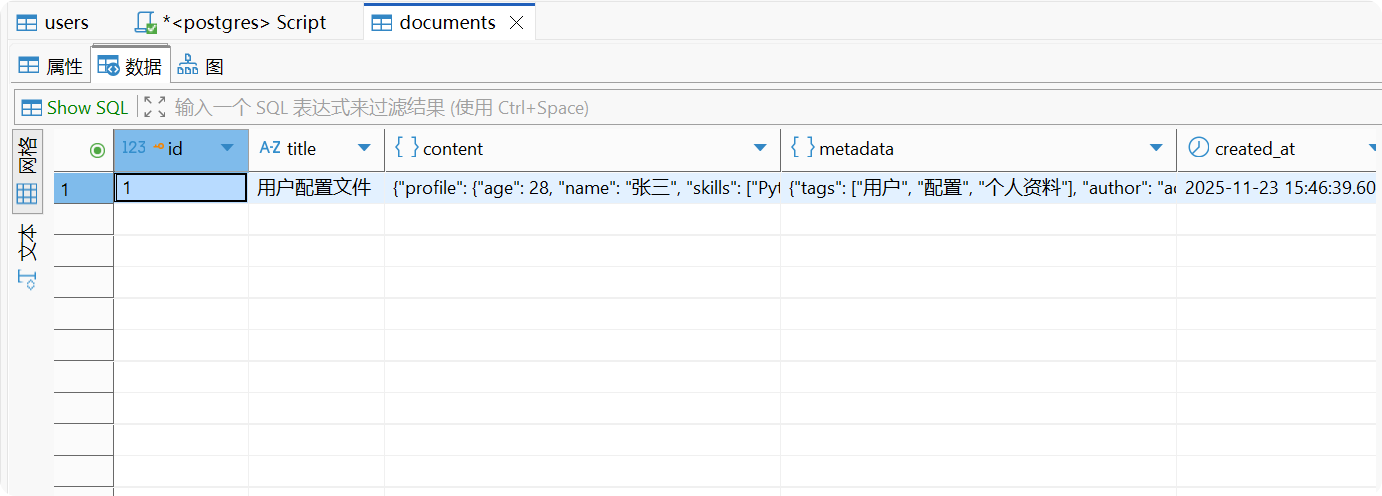
-- 创建包含JSONB的表CREATE TABLE documents ( id SERIAL PRIMARY KEY, title VARCHAR(200), content JSONB, metadata JSONB, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
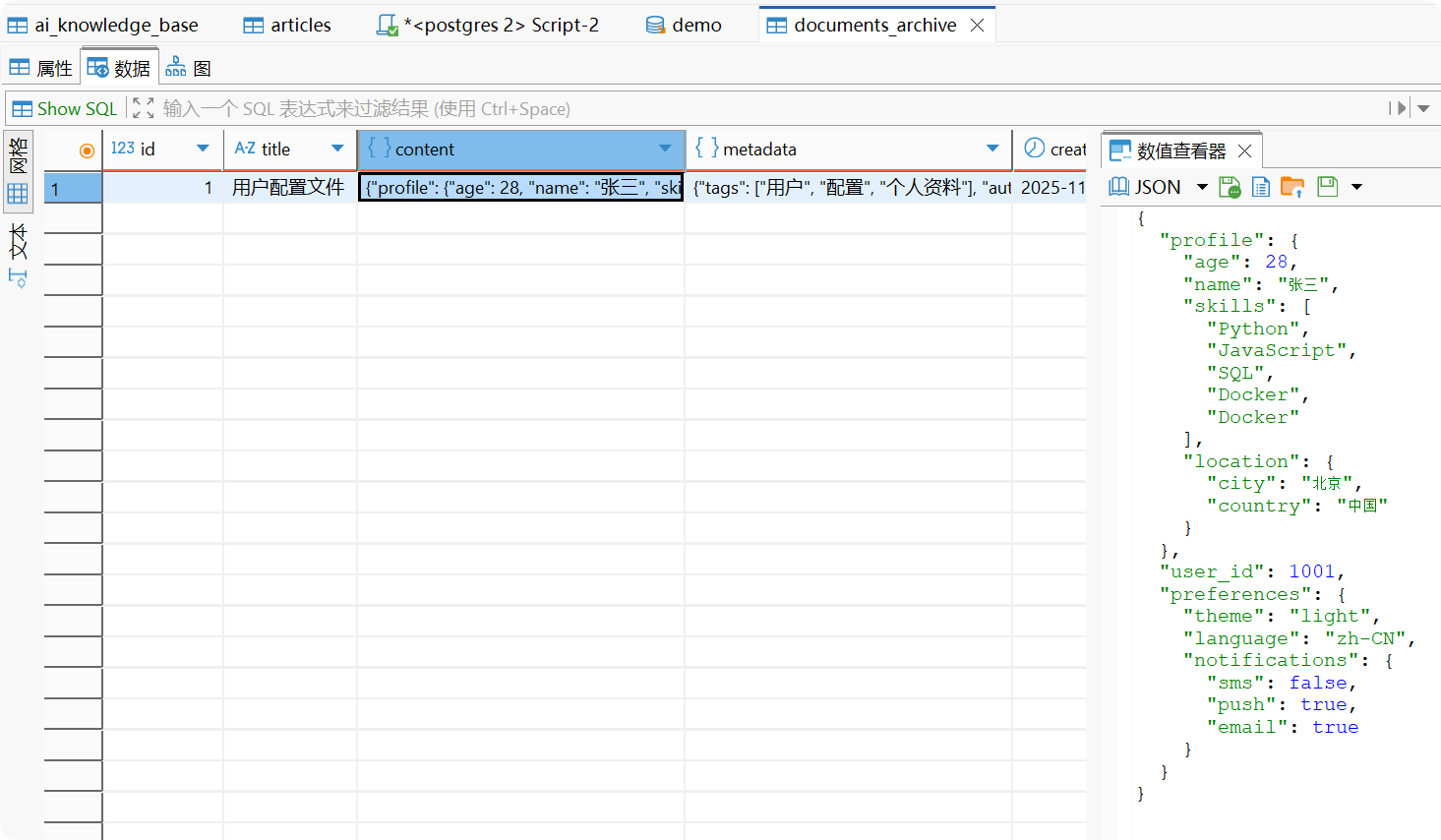
-- 插入JSON文档INSERT INTO documents (title, content, metadata)VALUES ( '用户配置文件', '{ "user_id": 1001, "preferences": { "theme": "dark", "language": "zh-CN", "notifications": { "email": true, "sms": false, "push": true } }, "profile": { "name": "张三", "age": 28, "skills": ["Python", "JavaScript", "SQL"] } }'::jsonb, '{ "version": "1.0", "author": "admin", "tags": ["用户", "配置", "个人资料"] }'::jsonb);分解解释:
::jsonb: 这是类型转换语法。它的意思是:“把我前面的这个字符串,转换成 JSONB 数据类型”。
- PostgreSQL 会解析这个字符串,验证它是否为合法的 JSON 格式。
- 如果格式正确,它会将 JSON 文档转换成一种高效的二进制格式存储起来。
JSONB相对于另一个类型JSON的优势在于它存储效率更高,并且支持索引,查询速度更快。
4.2 JSONB查询操作
-- 基本JSON路径查询SELECT title, content->'user_id' as user_idFROM documents;
-- 获取嵌套JSON值SELECT title, content->'preferences'->'theme' as theme, content->'preferences'->'notifications'->'email' as email_notifFROM documents;
-- JSON数组查询SELECT title, content->'profile'->'skills' as skillsFROM documents;
-- 检查JSON字段是否存在SELECT title FROM documentsWHERE content ? 'preferences';
-- 检查JSON数组是否包含特定值SELECT title FROM documentsWHERE content->'profile'->'skills' @> '["Python"]';
-- JSONB索引(提升查询性能)CREATE INDEX idx_documents_content_gin ON documents USING gin (content);
-- 创建部分索引CREATE INDEX idx_documents_user_id ON documents USING gin ((content->'user_id'))WHERE content ? 'user_id';4.3 JSONB修改操作
-- 更新JSON字段UPDATE documentsSET content = jsonb_set( content, '{preferences,theme}', '"light"')WHERE id = 1;
-- 添加新的JSON字段UPDATE documentsSET content = jsonb_insert( content, '{profile,location}', '{"city": "北京", "country": "中国"}'::jsonb)WHERE id = 1;
-- 删除JSON字段UPDATE documentsSET content = content - 'temp_field'WHERE content ? 'temp_field';
-- 追加到JSON数组UPDATE documentsSET content = jsonb_set( content, '{profile,skills}', content->'profile'->'skills' || '["Docker"]')WHERE id = 1;5:替换Elasticsearch - 全文搜索

要理解 PostgreSQL 的 FTS,首先需要了解几个核心概念:
- 文档:被搜索的基本单位。在数据库中,这通常是一个表中的一行,或者一个表中的一列(如文章标题、正文等)。
- 词元化:将文档分解为更小的、有意义的单元(称为词元)的过程。这个过程包括:
- 移除标点符号。
- 将单词转换为小写。
- 移除停用词,如
a,an,the,is等(这些词频率高,但搜索价值低)。 - 词干提取,例如将
running,ran转换为run。
- 数据类型: tsvector和tsquery
tsvector: “已排序的词元向量”。它是一个经过预处理、优化后的文档表示形式,包含了所有词元及其在文档中的位置信息。所有全文搜索都基于tsvector。tsquery: “查询表达式”。它同样是一个经过词元化处理的搜索条件,可以包含逻辑操作符(&- AND,|- OR,!- NOT)和短语搜索(<->- “followed by”)。
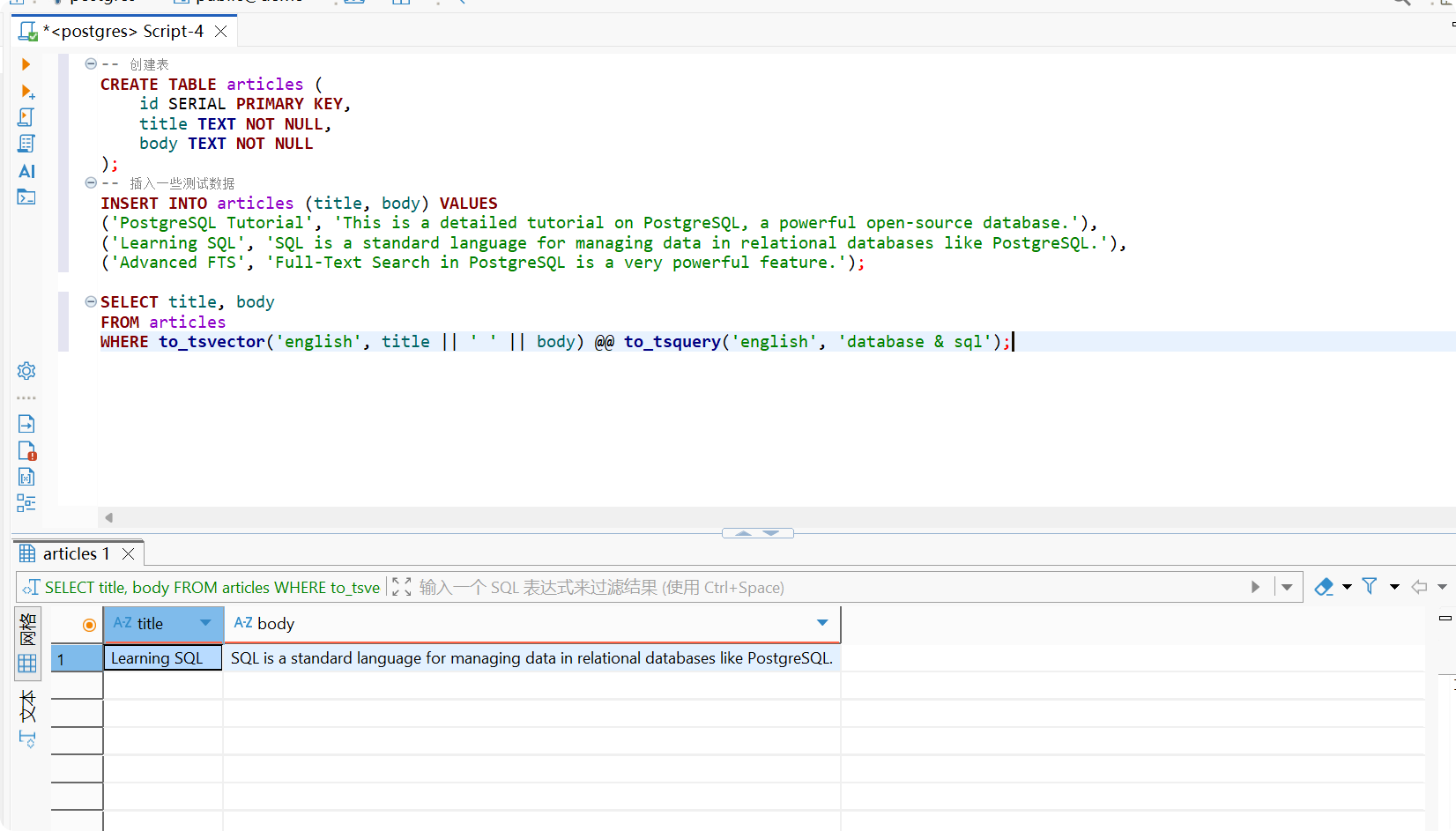
-- 创建表CREATE TABLE articles ( id SERIAL PRIMARY KEY, title TEXT NOT NULL, body TEXT NOT NULL);-- 插入一些测试数据INSERT INTO articles (title, body) VALUES('PostgreSQL Tutorial', 'This is a detailed tutorial on PostgreSQL, a powerful open-source database.'),('Learning SQL', 'SQL is a standard language for managing data in relational databases like PostgreSQL.'),('Advanced FTS', 'Full-Text Search in PostgreSQL is a very powerful feature.');
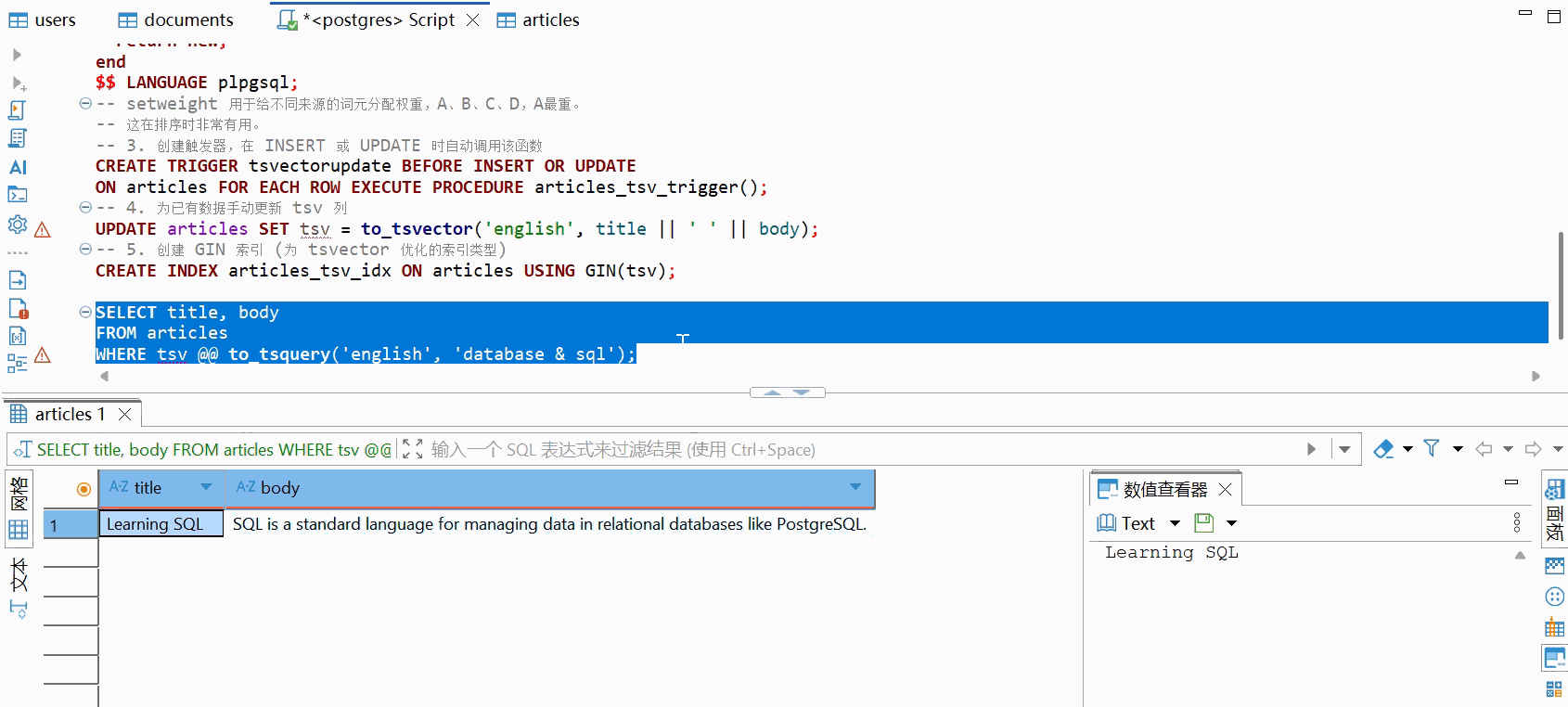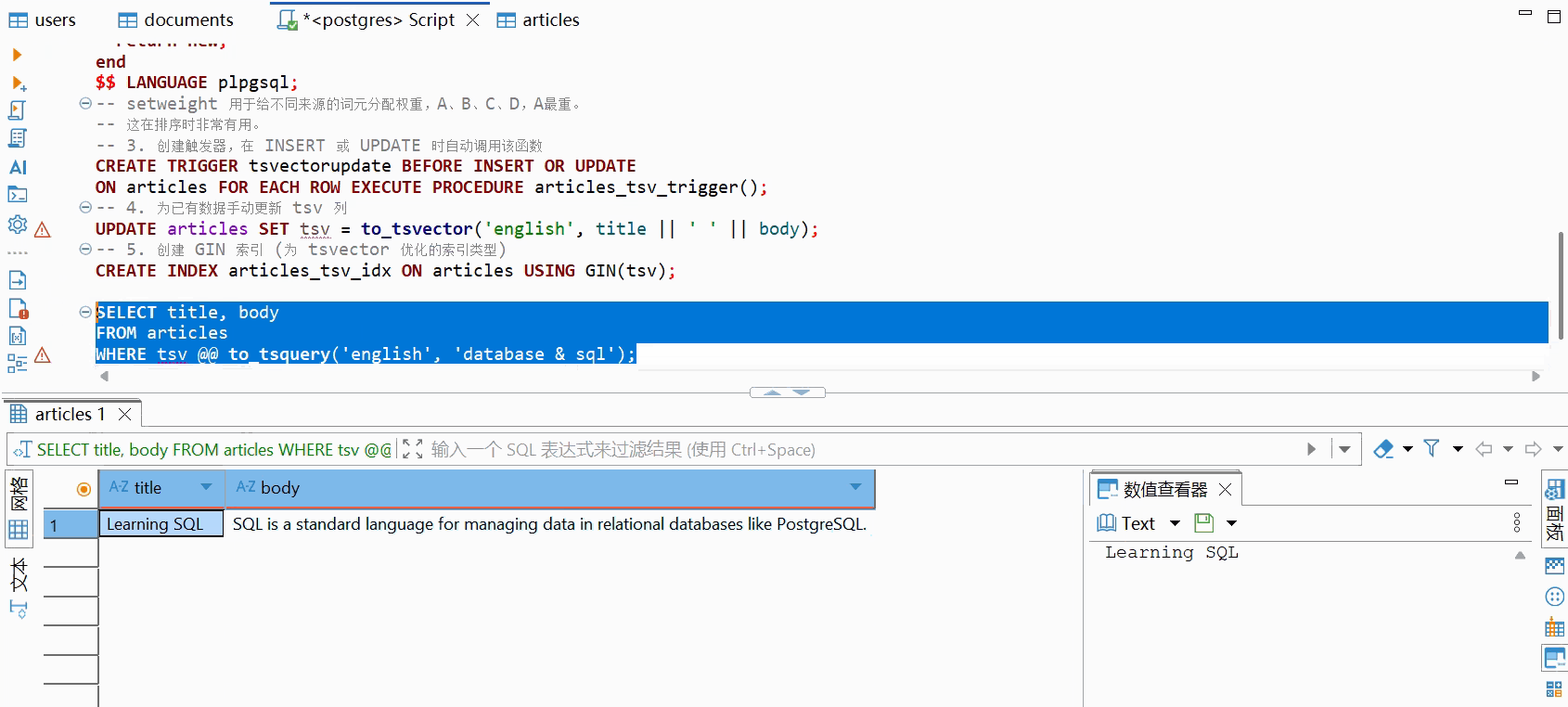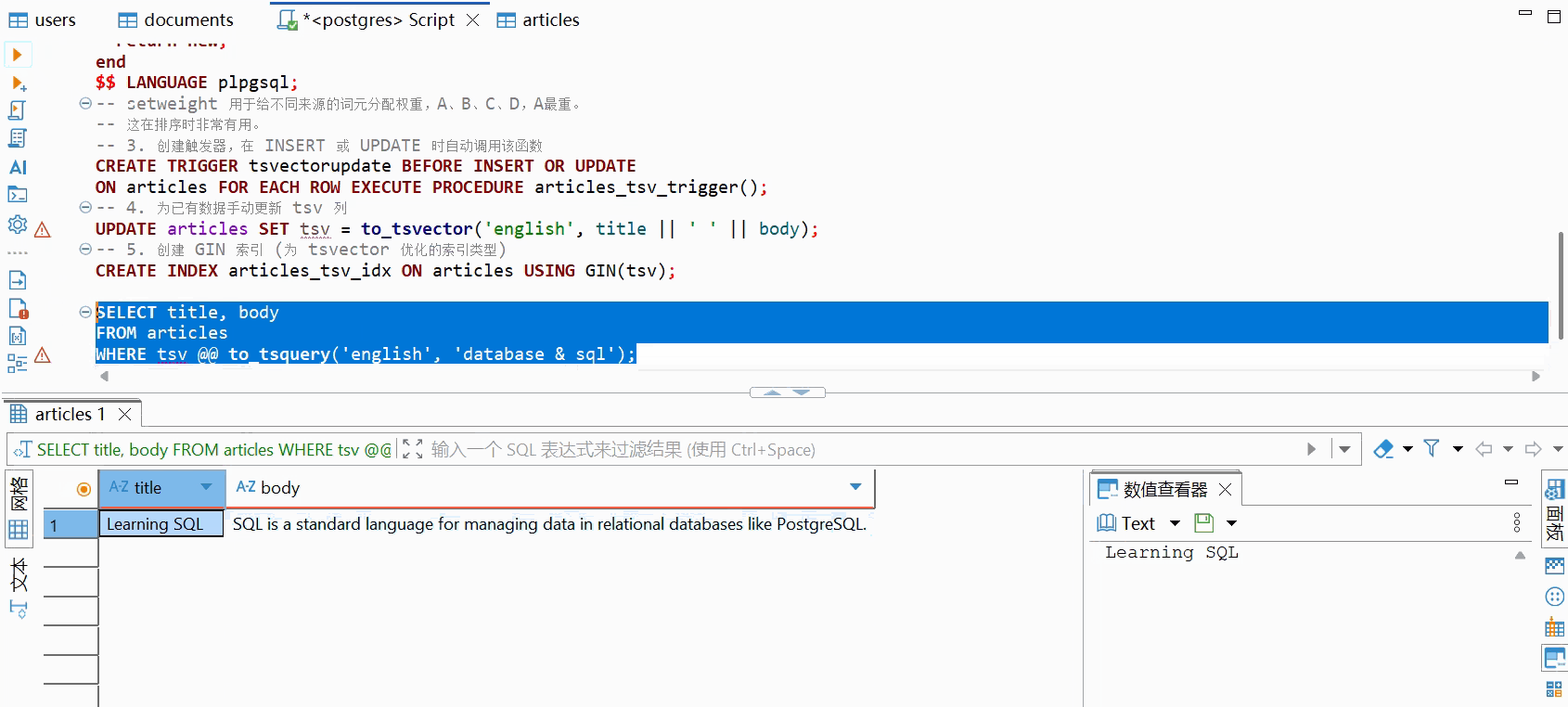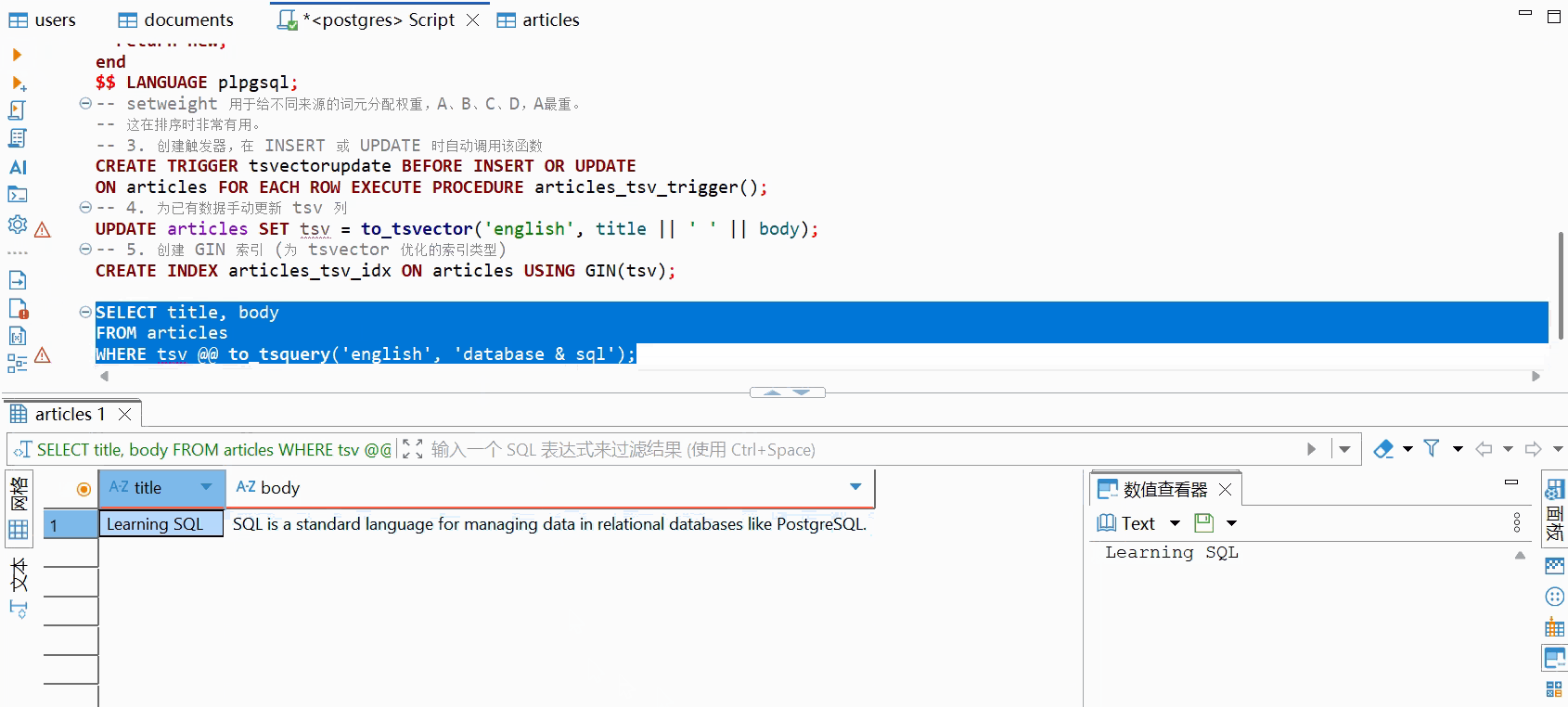
SELECT title, bodyFROM articlesWHERE to_tsvector('english', title || ' ' || body) @@ to_tsquery('english', 'database & sql');查询
-- 1. 添加 tsvector 列ALTER TABLE articles ADD COLUMN tsv tsvector;
-- 2. 创建一个函数来自动更新 tsv 列CREATE OR REPLACE FUNCTION articles_tsv_trigger() RETURNS trigger AS $$begin new.tsv := setweight(to_tsvector('english', coalesce(new.title,'')), 'A') || setweight(to_tsvector('english', coalesce(new.body,'')), 'B'); return new;end$$ LANGUAGE plpgsql;
-- setweight 用于给不同来源的词元分配权重,A、B、C、D,A最重。-- 这在排序时非常有用。
-- 3. 创建触发器,在 INSERT 或 UPDATE 时自动调用该函数CREATE TRIGGER tsvectorupdate BEFORE INSERT OR UPDATEON articles FOR EACH ROW EXECUTE PROCEDURE articles_tsv_trigger();
-- 4. 为已有数据手动更新 tsv 列UPDATE articles SET tsv = to_tsvector('english', title || ' ' || body);
-- 5. 创建 GIN 索引 (为 tsvector 优化的索引类型)CREATE INDEX articles_tsv_idx ON articles USING GIN(tsv);-- 新的、高性能的查询方式SELECT title, bodyFROM articlesWHERE tsv @@ to_tsquery('english', 'database & sql');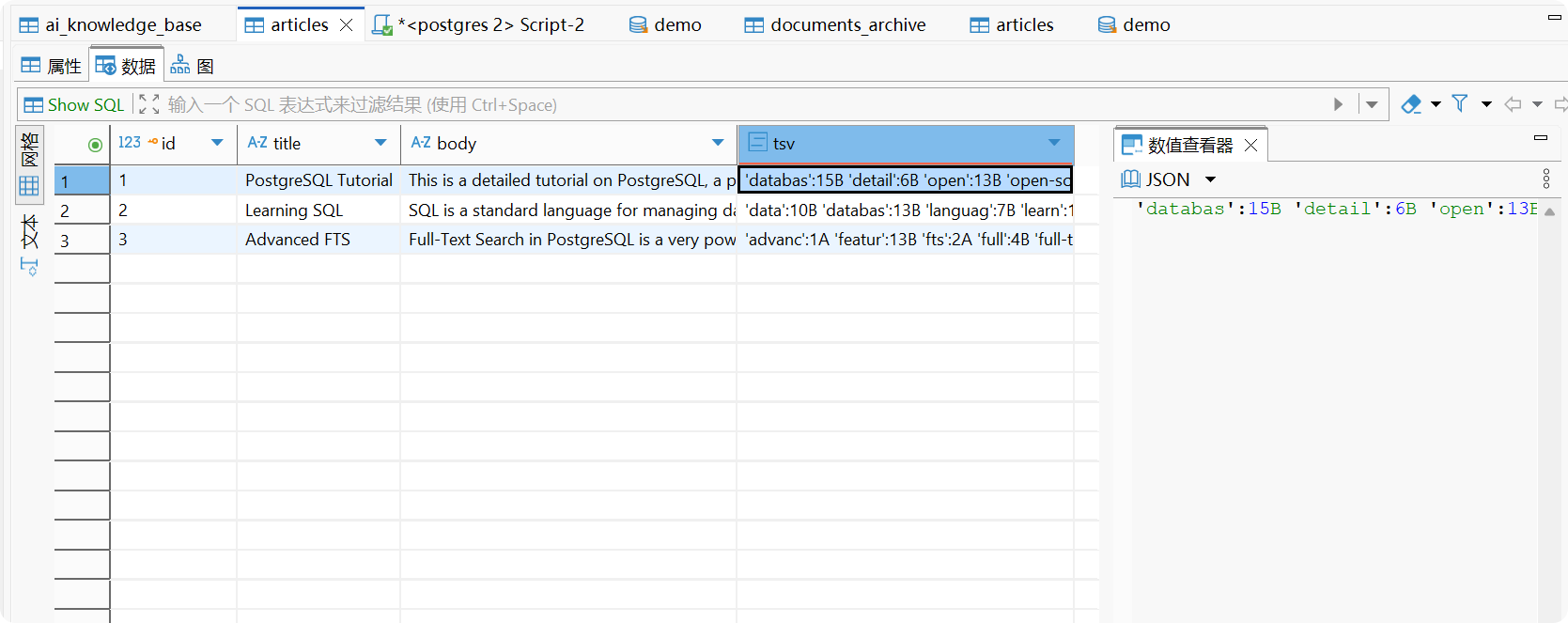
中文全文搜索得安装插件,zhparser或者 PGroonga,因为这边是Windows安装不如Linux简单,这边就不做演示了
6:AI知识库 - 向量搜索支持
6.1 安装向量扩展pgvector
Linux/macOS安装
# Ubuntu/Debian安装pgvectorsudo apt install postgresql-16-pgvector6.2 创建向量数据库
-- 启用向量扩展CREATE EXTENSION IF NOT EXISTS vector;
-- 创建AI知识库表CREATE TABLE ai_knowledge_base ( id SERIAL PRIMARY KEY, title VARCHAR(500) NOT NULL, content TEXT NOT NULL, embedding vector(5), -- OpenAI embedding维度 category VARCHAR(100), source VARCHAR(200), created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
-- 创建向量索引CREATE INDEX idx_ai_knowledge_embedding ON ai_knowledge_baseUSING ivfflat (embedding vector_cosine_ops)WITH (lists = 100);6.3 向量数据插入
-- 插入知识条目(示例embedding)INSERT INTO ai_knowledge_base (title, content, embedding, category, source) VALUES('什么是机器学习?', '机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习和改进,而无需明确编程。机器学习算法通过训练数据构建数学模型,以做出预测或决策。', '[-0.015, 0.032, -0.018, 0.041, 0.009]', '人工智能', 'AI教科书'),('PostgreSQL数据库优势', 'PostgreSQL是世界上最先进的开源关系型数据库,支持复杂查询、事务、并发控制,具有丰富的扩展功能,包括JSON支持、全文搜索、向量搜索等。', '[0.025, -0.014, 0.038, -0.002, 0.017]', '数据库', '技术文档'),('深度学习基础', '深度学习是机器学习的一个子领域,它使用多层神经网络来学习数据的复杂模式。深度学习在图像识别、自然语言处理等领域取得了突破性进展。', '[-0.008, 0.021, 0.015, -0.033, 0.012]', '人工智能', '深度学习教程');6.4 相似度搜索
-- 创建相似度搜索函数CREATE OR REPLACE FUNCTION find_similar_knowledge( query_embedding vector(5), similarity_threshold FLOAT DEFAULT 0.7, limit_count INTEGER DEFAULT 5)RETURNS TABLE(id INTEGER, title VARCHAR, content TEXT, similarity_score FLOAT) AS $$BEGIN RETURN QUERY SELECT kb.id, kb.title, kb.content, 1 - (kb.embedding <=> query_embedding) as similarity_score -- 计算 kb 表中某条记录的 embedding 向量与你传入的 query_embedding 向量之间的距离 FROM ai_knowledge_base kb WHERE 1 - (kb.embedding <=> query_embedding) > similarity_threshold -- 计算每一行的相似度分数,然后只保留那些大于你设定的阈值的行 ORDER BY kb.embedding <=> query_embedding LIMIT limit_count;END;$$ LANGUAGE plpgsql;
-- 创建RAG(检索增强生成)查询函数CREATE OR REPLACE FUNCTION retrieve_context_for_query( query_text TEXT, query_embedding vector(5))RETURNS TABLE(context TEXT, source_info VARCHAR) AS $$BEGIN RETURN QUERY SELECT kb.content, kb.title || ' - ' || kb.category as source_info FROM ai_knowledge_base kb WHERE 1 - (kb.embedding <=> query_embedding) > 0.6 ORDER BY kb.embedding <=> query_embedding LIMIT 3;END;$$ LANGUAGE plpgsql;7:定时任务 - pg_cron扩展

7.1 安装和配置pg_cron
Linux/macOS安装
# Ubuntu安装pg_cronsudo apt install postgresql-16-cron
# 修改postgresql.confvim /etc/postgresql/16/main/postgresql.confshared_preload_libraries = 'pg_cron'cron.database_name = 'postgres'
# 本地连接无需认证vim /etc/postgresql/16/main/pg_hba.confhost all all 127.0.0.1/32 trust7.2 启用扩展
-- 创建扩展CREATE EXTENSION IF NOT EXISTS pg_cron;7.3 常用定时任务示例
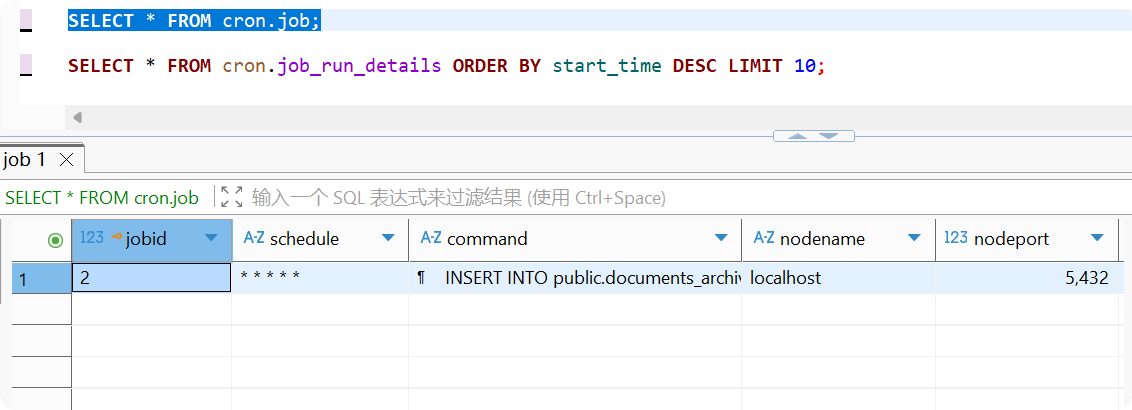
SELECT cron.schedule( 'documents-migration', -- 任务名称 '* * * * *', -- Cron表达式: 每分钟执行一次 $$ INSERT INTO public.documents_archive (id, title, "content", metadata, created_at) SELECT id, title, "content", metadata, created_at FROM public.documents WHERE id NOT IN (SELECT id FROM public.documents_archive); $$);查询任务设置
7.4 监控和管理
-- 查看所有定时任务SELECT * FROM cron.job;
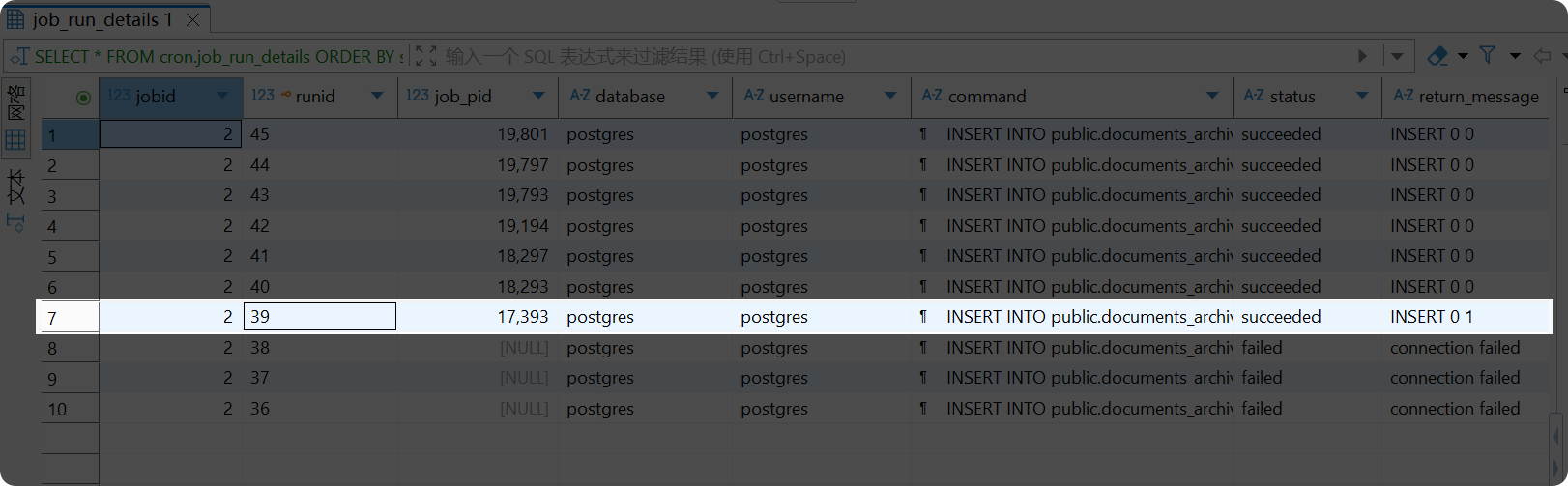
-- 查看任务执行历史SELECT * FROM cron.job_run_details ORDER BY starttime DESC LIMIT 10;
-- 取消定时任务SELECT cron.unschedule('cleanup-expired-data');
-- 更新定时任务SELECT cron.schedule('cleanup-expired-data', '0 1 * * *', 'VACUUM ANALYZE;');
-- 创建任务执行报告CREATE OR REPLACE FUNCTION generate_cron_report()RETURNS TABLE(job_name VARCHAR, last_run TIMESTAMP, next_run TIMESTAMP, status VARCHAR, total_runs BIGINT) AS $$BEGIN RETURN QUERY SELECT j.jobid::TEXT, MAX(r.starttime), j.schedule, CASE WHEN j.active THEN 'ACTIVE' ELSE 'INACTIVE' END, COUNT(r.runid) FROM cron.job j LEFT JOIN cron.job_run_details r ON j.jobid = r.jobid GROUP BY j.jobid, j.schedule, j.active;END;$$ LANGUAGE plpgsql;
-- 查看定时任务报告SELECT * FROM generate_cron_report();运行情况
效果
8:使用 UNLOGGED 缓存
PostgreSQL 的正常表(我们称之为 “logged” 表)在每次数据修改(INSERT, UPDATE, DELETE)时,都会做两件重要的事情来保证数据的安全(所谓的 ACID 特性):
- 修改数据文件:将数据实际写入到磁盘上的数据文件中。
- 写入预写式日志:将这次操作的详细信息(比如“在A表的第X行,把Y值改成Z”)先写入到一个叫做 WAL (Write-Ahead Logging) 的特殊文件中。
这个 WAL 非常关键,它是数据库崩溃后恢复数据的保证。即使数据文件还没来得及完全同步到磁盘,只要 WAL 文件还在,PostgreSQL 就能在重启后“重放”这些日志,把数据库恢复到崩溃前的状态。
而 UNLOGGED 表,顾名思义,它跳过了第二步——写入 WAL。
当你对一个 UNLOGGED 表进行数据修改时,PostgreSQL 只会修改内存中的数据页,然后在某个时机刷写到磁盘的数据文件上,但这个过程不会被记录到 WAL 中。
-- 创建一个 UNLOGGED 表CREATE UNLOGGED TABLE fast_data ( id SERIAL PRIMARY KEY, message TEXT, created_at TIMESTAMPTZ DEFAULT NOW());-- 插入数据 (这会很快)INSERT INTO fast_data (message) VALUES ('test message 1'), ('test message 2');-- 查询数据SELECT * FROM fast_data;
| 特性 | UNLOGGED 表 | 临时表 |
|---|---|---|
| 作用域 | 对所有会话可见。 | 只对创建它的会话可见。会话结束,表自动删除。 |
| 数据持久性 | 在服务器正常运行时持久,但服务器崩溃后数据丢失。 | 会话结束后数据丢失。 |
| WAL | 不写 WAL。 | 不写 WAL。 |
| 索引 | 可以创建普通的 B-Tree, GIN 等索引。 | 也可以创建索引,但索引也是临时的。 |
| 主要用途 | 会话间共享的、高性能的、可重建的数据暂存区。 | 单个会话内部的、临时的、复杂的查询或数据处理。 |
9:数据库变API - PostgREST

PostgREST将PostgreSQL转换为REST API的架构
它能让你仅凭一个 PostgreSQL 数据库,就自动获得一个功能完备的 RESTful API,而无需写任何后端代码(如 Node.js, Python, Go 等)
总结
核心优势
- 对象-关系特性:支持复合类型、继承、数组等高级数据结构
- 文档数据库能力:JSON/JSONB支持可替代MongoDB
- 全文搜索引擎:内置全文搜索可替代Elasticsearch
- 向量数据库:pgvector扩展支持AI应用
- 定时任务:pg_cron提供任务调度能力
- 内存缓存:pg_prewarm优化性能
- API服务:PostgREST直接将数据库转为API
适用场景
- 中小型企业应用:一个数据库解决多种需求,降低架构复杂度
- 快速原型开发:快速构建MVP,无需集成多个系统
- 数据密集型应用:复杂查询、实时分析、全文搜索
- AI/ML应用:向量存储、语义搜索、知识库构建
- 企业级应用:高并发、事务一致性、数据安全
PostgreSQL以其强大的扩展能力和丰富的功能,确实可以胜任”全栈数据库”的角色,为开发者提供了一个统一、强大、可靠的数据平台。